
At Etsy, we’re focused on elevating the best of our marketplace to help creative entrepreneurs grow their businesses. We continue to invest in making Etsy a safe and trusted place to shop, so sellers’ extraordinary items can shine.
Today, there are more than 100 million unique items available for sale on our marketplace, and our vibrant global community is made up of over 90 million active buyers and 7 million active sellers, the majority of whom are women and sole owners of their creative businesses. To support this growing community, our Trust & Safety team of Product, Engineering, Data, and Operations experts are dedicated to keeping Etsy’s marketplace safe by enforcing our policies and removing potentially violating or infringing items at scale
For that, we make use of community reporting and automated controls for removing this potentially violating content. In order to continue to scale and enhance our detections through innovative products and technologies, we also leverage state-of-the-art Machine Learning solutions which we have already used to identify and remove over 100,000 violations during the past year on our marketplace. In this article, we are going to describe one of our systems to detect policy violations that utilizes supervised learning, a family of algorithms that uses data to train their models to recognize patterns and predict outcomes.
Datasets
In Machine Learning, data is one of the variables we have the most control over. Extracting data and building trustworthy datasets is a crucial step in any learning problem. In Trust & Safety, we are determined to keep our marketplace and users safe by identifying violations to our policies.
For that, we log and annotate potential violations that enable us to collect datasets reliably. In our approach, these are translated into positives, these were indeed violations, and negatives, these were found not to be offending for a given policy. The latter are also known as hard negatives as they are close to our positives and can help us to better learn how to partition these two sets.
In addition, we also add easy or soft negatives by adding random items to our datasets. This allows us to give further general examples to our models for listings that do not violate any policy, which is the majority in our marketplace and improve generalizability. The number of easy negatives to add is a hyper-parameter to tune, more will mean higher training time and fewer positive representations.
For each training example, we extract multimodal signals, both textual and imagery from our listings.
Then, we split our datasets by time using progressive evaluation, to mimic our production usecase and learn to adapt to recent behavior. These are split into training, used to train our models and learn patterns, validation to fine tune our training hyper-parameters such as learning rate and to evaluate over-fitting, and test to report our metrics in an unbiased manner.
Model Architecture
After usual transformations and extraction of a set of offline features from our datasets, we are all set to start training our Machine Learning model.
The goal is to predict whether a given listing violates any of our predefined set of policies, or in contrast, it doesn’t violate any of them. For that, we added a neutral class that depicts the no violation class, where the majority of our listings fall into. This is a typical design pattern for these types of problems.
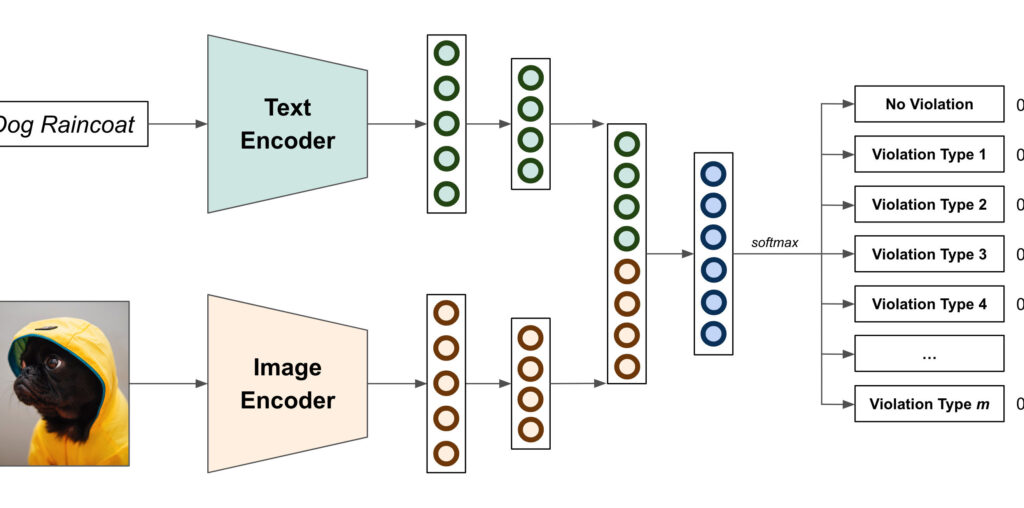
Our model architecture includes a text encoder and an image encoder to learn representations (aka embeddings) for each modality.
Our text encoder currently employs a BERT-based architecture to extract context-full representations of our text inputs. In addition, to alleviate compute time, we leverage ALBERT, a lighter BERT with 90% fewer parameters as the transformer blocks share them. Our initial lightweight representation used an in-house model trained for Search usecases. This allowed us to quickly start iterating and learning from this problem.
Our image encoder currently employs EfficientNet, a very efficient and accurate Convolutional Neural Network (CNN). Our initial lightweight representation used an in-house model for category classification using CNNs. We are experimenting with transformer-based architectures, similar to our text encoders, with vision transformers but its performance has not been significantly improved.
Inspired by EmbraceNet, our architecture then further learns more constrained representations for both text and image embeddings separately, before they are concatenated to form a unique multimodal representation. This is then sent to a final softmax activation that maps logits to probabilities for our internal use.
In addition, in order to address the imbalanced nature of this problem, we leverage focal loss that penalizes more hard misclassified examples.
Figure 1 shows our model architecture with late concatenation of our text and image encoders and final output probabilities on an example.

Model Evaluation
First, we experimented and iterated by training our model offline. To evaluate its performance, we established certain benchmarks, based on the business goal of minimizing the impact of any well-intentioned sellers while successfully detecting any offending listings in the platform. This results in a typical evaluation trade-off between precision and recall, precision being the fraction of correct predictions over all predictions made, and recall being the fraction of correct predictions over the actual true values. However, we faced the challenge that recall is not possible to compute, as it’s not feasible to manually review the millions and millions of new listings per day so we had to settle for a proxy for recall from what has been annotated.
Once we had a viable candidate to test in production, we deployed our model as an endpoint and built a service to perform pre-processing and post-processing steps before and after the call to our endpoint that can be called via an API.
Then, we ran an A/B test to measure its performance in production using a canary release approach, slowly rolling out our new detection system to a small percentage of traffic that we keep increasing while we validate an increase in our metrics and no unexpected computation overload.
Afterwards, we iterated and every time we had a promising offline candidate, named challenger, that improved our offline performance metrics, we A/B tested it with respect to our current model, named champion. We designed guidelines for model promotion to increase our metrics and our policy coverage.
Now, we monitor and observe our model predictions and trigger re-training when our performance degrades.
Results
Our supervised learning system has been continually learning as we train frequently, run experiments with new datasets and model architectures, A/B test them and deploy them in production. We have added violations as additional classes to our model. As a result, we have identified and removed more than 100,000 violations using these methodologies, in addition to other tools and services that continue to detect and remove violations.
This is one of our approaches to identify potentially offending content among others such as explicitly using the policy information and leverage the latest in Large Language Models (LLMs) and Generative AI. Stay tuned!
“To infinity and beyond!” –Buzz Lightyear, Toy Story