
Introduction
Personalization is vital to connect our unique marketplace to the right buyer at the right time. Etsy has recently introduced a novel, general approach to personalizing ML models based on encoding and learning from short-term (one-hour) sequences of user actions through a reusable three-component deep learning module, the adSformer Diversifiable Personalization Module (ADPM). We describe in detail our method in our recent paper, with an emphasis on personalizing the CTR (clickthrough rate) and PCCVR (post-click conversion rate) ranking models we use in Etsy Ads. Here, we’d like to present a brief overview.
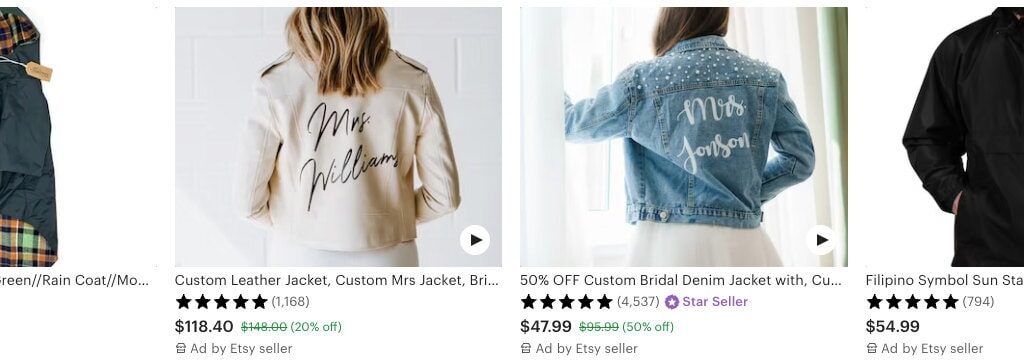
Etsy offers its sellers the opportunity to place sponsored listings as a supplement to the organic results returned by Etsy search. For sellers and buyers alike, it’s important that those sponsored listings be as relevant to the user’s intent as possible. As Figure 1 suggests, when it comes to search, a “jacket” isn’t always just any jacket:


For ads to be relevant, they need to be personalized.
If we define a “session” as a one-hour shopping window, and make a histogram of the total number of listings viewed across a sample of sessions (Fig. 2), we see that a power law distribution emerges. The vast majority of users interact with only a small number of listings before leaving their sessions.

Understood simply in terms of listing views, it might seem that session personalization would be an insurmountable challenge. To overcome this challenge we leverage a rich stream of user actions surrounding those views and communicating intent, for example: search queries, item favorites, views, add-to-carts, and purchases. Our rankers can optimize the shopping experience in the moment by utilizing streaming features being made available within seconds of these user actions.
Consider a hypothetical sequence of lamps viewed by a buyer within the last hour.

Not only is the buyer looking within a particular set of lamps (orange, mushroom-shaped), but they arrived at these lamps through a sequence of query refinements. The search content itself contains information about the visual and textual similarities between the listings, and the order in which the queries occur adds another dimension of information. The content and the sequence of events can be used together to infer what is driving the user’s current interest in lamps.
adSformer Diversifiable Personalization Module
The adSformer Diversifiable Personalization Module (ADPM), illustrated on the left hand side of Figure 4, is Etsy’s solution for using temporal and content signals for session personalization. A dynamic representation of the user is generated from a sequence of the user’s most recent streamed actions. The input sequence contains item IDs, queries issued and categories viewed. We consider the item IDs, queries, and categories as “entities” that have recent interactions within the session. For each of these entities we consider different types of actions within a user session–views, recent cart-adds, favorites, and purchases–and we encode each type of entity/action pair separately. This lets us capture fine-grained information about the user’s interests in their current session.

Through ablation studies we found that ADPM’s three components work together symbiotically to outperform experiments where each component is considered independently. Furthermore, in deployed applications, the diversity of learned signals improves robustness to input distribution shifts. It also leads to more relevant personalized results, because we understand the user from multiple perspectives. Here is how the three components operate:
-
Component One: The adSformer Encoder
The adSformer encoder component uses one or more custom adSformer blocks illustrated in the right panel of Figure 4. This component learns a deep, expressive representation of the one-hour input sequence. The adSformer block modifies the standard transformer block in the attention literature by adding a final global max pooling layer. The pooling layer downsamples the block’s outputs by extracting the most salient signals from the sequence representation instead of outputting the fully concatenated standard transformer output. Formally, for a user, for a one-hour sequence S of viewed item IDs, the adSformer encoder is defined as the output of a stack of layers g(x), where x is the output of each previous layer and o1 is the component’s output. The first layer is an embedding of item and position.


-
Component Two: Pretrained Representations. Component two employs pretrained embeddings of item IDs that users have interacted with together with average pooling to encode the one-hour sequence of user actions. Depending on downstream performance and availability, we choose from multimodal (AIR) representations and visual representations. Thus component two encodes rich image, text and multimodal signals from all the items in the sequence. The advantage of leveraging pretrained item embeddings is that these rich representations are learned efficiently offline using complex deep learning architectures that would not be feasible online in real time. Formally, for a given one-hour sequence of m1hr item IDs pretrained d-dimensional embedding vectors e, we compute a sequence representation as

- Component Three: Representations Learned “On the Fly”
The third component of ADPM introduces representations learned for each sequence from scratch in its own vector space as part of the downstream models. This component learns lightweight representations for many different sequences for which we do not have pretrained representations available, for example sequences of favorited shop ids. Formally, for z one-hour sequences of entities acted upon S we learn embeddings for each entity and sequence to obtain the component’s output o3 as

The intermediary outputs of the three components are concatenated to form the final ADPM output, the dynamic user representation u. This user representation is then concatenated to the input vector in various rankers or recommenders we want to real-time personalize. Formally, for one-hour variable length sequences of user actions S, and ADPM’s components outputs o

From a software perspective, the module is implemented as a Tensorflow Keras module which can easily be employed in downstream models through a simple import statement.
Pretrained Representation Learning
The second component of the ADPM includes pretrained representations. We rely on several pretrained representations: image embeddings, text embeddings, and multimodal item representations.
Visual Representations
In Etsy Ads, we employ image signals across a variety of tasks, such as visually similar candidate generation, search by image, as inputs for learning other pretrained representations, and in the ADPM’s second component. To effectively leverage the rich signal encoded in Etsy Ads images we train image embeddings in a multitask classification learning paradigm. By using multiple classification heads, such as taxonomy, color, and material, our representations are able to capture more diverse information about the image. So far we have derived great benefit from our multitask visual embeddings, trained using a lightweight EfficientNetB0 architecture, and weights pretrained on ImageNet as backbone. We replaced the final layer with a 256-dimensional convolutional block, which becomes the output embedding. We apply image random rotation, translation, zoom, and a color contrast transformation to augment the dataset during training. We are currently in the process of updating the backbone architectures to efficient vision transformers to further improve the quality of the image representations and the benefits derived in downstream applications, including the ADPM.
Ads Information Retrieval Representations
Ads Information Retrieval (AIR) item representations encode an item ID through a metric learning approach, which aims to learn a distance function or similarity metric between two items. Standard approaches to metric learning include siamese networks, contrastive loss, and triplet loss. However, we found more interpretable results using a sampled in-batch softmax loss. This method treats each batch as a classification problem pairing all the items in a batch that were co-clicked. A pseudo-two-tower architecture is used to encode the source items and candidate items towers which share all trainable weights across both towers. Each item tower captures and encodes information about an item’s title, image, primary color, attributes, category, etc. This information diversity is key to our personalization outcomes. By leveraging a variety of data sources, the system can identify patterns and insights that would be missed by a more limited set of inputs.
ADPM-Personalized Sponsored Search
ADPM’s effectiveness and generality is demonstrated in the way we use it to personalize the CTR prediction model in EtsyAds’ Sponsored Search. The ADPM encodes reverse-chronological sequences of recent user actions (in the sliding one-hour window we’ve discussed), anywhere on Etsy, for both logged-in and logged-out users. We concatenate ADPM’s output, the dynamic user representation, to the rest of the wide input vector in the CTR model. To fully leverage this even wider input vector, a deep and cross (DCN) interaction module is included in the overall CTR architecture. If we remove the DCN module, the CTR’s model ROC-AUC drops by 1.17%. The architecture of the ADPM-personalized CTR prediction model employed by EtsyAds in sponsored search is given in Figure 5. (We also employ the ADPM to personalize the PCCVR model with a similar architecture, which naturally led to ensembling the two models in a multitask architecture, a topic beyond the scope of this blog post.)

The ADPM-personalized CTR and PCCVR models outperformed the CTR and PCCVR non-personalized production baselines by +2.66% and +2.42%, respectively, in offline Area Under the Receiver Operating Characteristic Curve (ROC-AUC). Following the robust online gains in A/B tests, we deployed the ADPM-personalized sponsored search system to 100% of traffic.
Conclusion
The adSformer diversifiable personalization module (ADPM) is a scalable, general approach to model personalization from short-term sequences of recent user actions. Its use in sponsored search to personalize our ranking and bidding models is a milestone for EtsyAds, and is delivering greater relevance in sponsored placements for the millions of buyers and sellers that Etsy’s marketplace brings together. If you would like more details about ADPM, please see our paper.