
Since the release of ChatGPT in November 2022, the GenAI
landscape has undergone rapid cycles of experimentation, improvement, and
adoption across a wide range of use cases. Applied to the software
engineering industry, GenAI assistants primarily help engineers write code
faster by providing autocomplete suggestions and generating code snippets
based on natural language descriptions. This approach is used for both
generating and testing code. While we recognise the tremendous potential of
using GenAI for forward engineering, we also acknowledge the significant
challenge of dealing with the complexities of legacy systems, in addition to
the fact that developers spend a lot more time reading code than writing it.
Through modernizing numerous legacy systems for our clients, we have found that an evolutionary approach makes
legacy displacement both safer and more effective at achieving its value goals. This method not only reduces the
risks of modernizing key business systems but also allows us to generate value early and incorporate frequent
feedback by gradually releasing new software throughout the process. Despite the positive results we have seen
from this approach over a “Big Bang” cutover, the cost/time/value equation for modernizing large systems is often
prohibitive. We believe GenAI can turn this situation around.
For our part, we have been experimenting over the last 18 months with
LLMs to tackle the challenges associated with the
modernization of legacy systems. During this time, we have developed three
generations of CodeConcise, an internal modernization
accelerator at Thoughtworks . The motivation for
building CodeConcise stemmed from our observation that the modernization
challenges faced by our clients are similar. Our goal is for this
accelerator to become our sensible default in
legacy modernization, enhancing our modernization value stream and enabling
us to realize the benefits for our clients more efficiently.
We intend to use this article to share our experience applying GenAI for Modernization. While much of the
content focuses on CodeConcise, this is simply because we have hands-on experience
with it. We do not suggest that CodeConcise or its approach is the only way to apply GenAI successfully for
modernization. As we continue to experiment with CodeConcise and other tools, we
will share our insights and learnings with the community.
GenAI era: A timeline of key events
One primary reason for the
current wave of hype and excitement around GenAI is the
versatility and high performance of general-purpose LLMs. Each new generation of these models has consistently
shown improvements in natural language comprehension, inference, and response
quality. We are seeing a number of organizations leveraging these powerful
models to meet their specific needs. Additionally, the introduction of
multimodal AIs, such as text-to-image generative models like DALL-E, along
with AI models capable of video and audio comprehension and generation,
has further expanded the applicability of GenAIs. Moreover, the
latest AI models can retrieve new information from real-time sources,
beyond what is included in their training datasets, further broadening
their scope and utility.
Since then, we have observed the emergence of new software products designed
with GenAI at their core. In other cases, existing products have become
GenAI-enabled by incorporating new features previously unavailable. These
products typically utilize general purpose LLMs, but these soon hit limitations when their use case goes beyond
prompting the LLM to generate responses purely based on the data it has been trained with (text-to-text
transformations). For instance, if your use case requires an LLM to understand and
access your organization’s data, the most economically viable solution often
involves implementing a Retrieval-Augmented Generation (RAG) approach.
Alternatively, or in combination with RAG, fine-tuning a general-purpose model might be appropriate,
especially if you need the model to handle complex rules in a specialized
domain, or if regulatory requirements necessitate precise control over the
model’s outputs.
The widespread emergence of GenAI-powered products can be partly
attributed to the availability of numerous tools and development
frameworks. These tools have democratized GenAI, providing abstractions
over the complexities of LLM-powered workflows and enabling teams to run
quick experiments in sandbox environments without requiring AI technical
expertise. However, caution must be exercised in these relatively early
days to not fall into traps of convenience with frameworks to which
Thoughtworks’ recent technology radar
attests.
Problems that make modernization expensive
When we began exploring the use of “GenAI for Modernization”, we
focused on problems that we knew we would face again and again – problems
we knew were the ones causing modernization to be time or cost
prohibitive.
- How can we understand the existing implementation details of a system?
- How can we understand its design?
- How can we gather knowledge about it without having a human expert available
to guide us? - Can we help with idiomatic translation of code at scale to our desired tech
stack? How? - How can we minimize risks from modernization by improving and adding
automated tests as a safety net? - Can we extract from the codebase the domains, subdomains, and
capabilities? - How can we provide better safety nets so that differences in behavior
between old systems and new systems are clear and intentional? How do we enable
cut-overs to be as headache free as possible?
Not all of these questions may be relevant in every modernization
effort. We have deliberately channeled our problems from the most
challenging modernization scenarios: Mainframes. These are some of the
most significant legacy systems we encounter, both in terms of size and
complexity. If we can solve these questions in this scenario, then there
will certainly be fruit born for other technology stacks.
The Architecture of CodeConcise
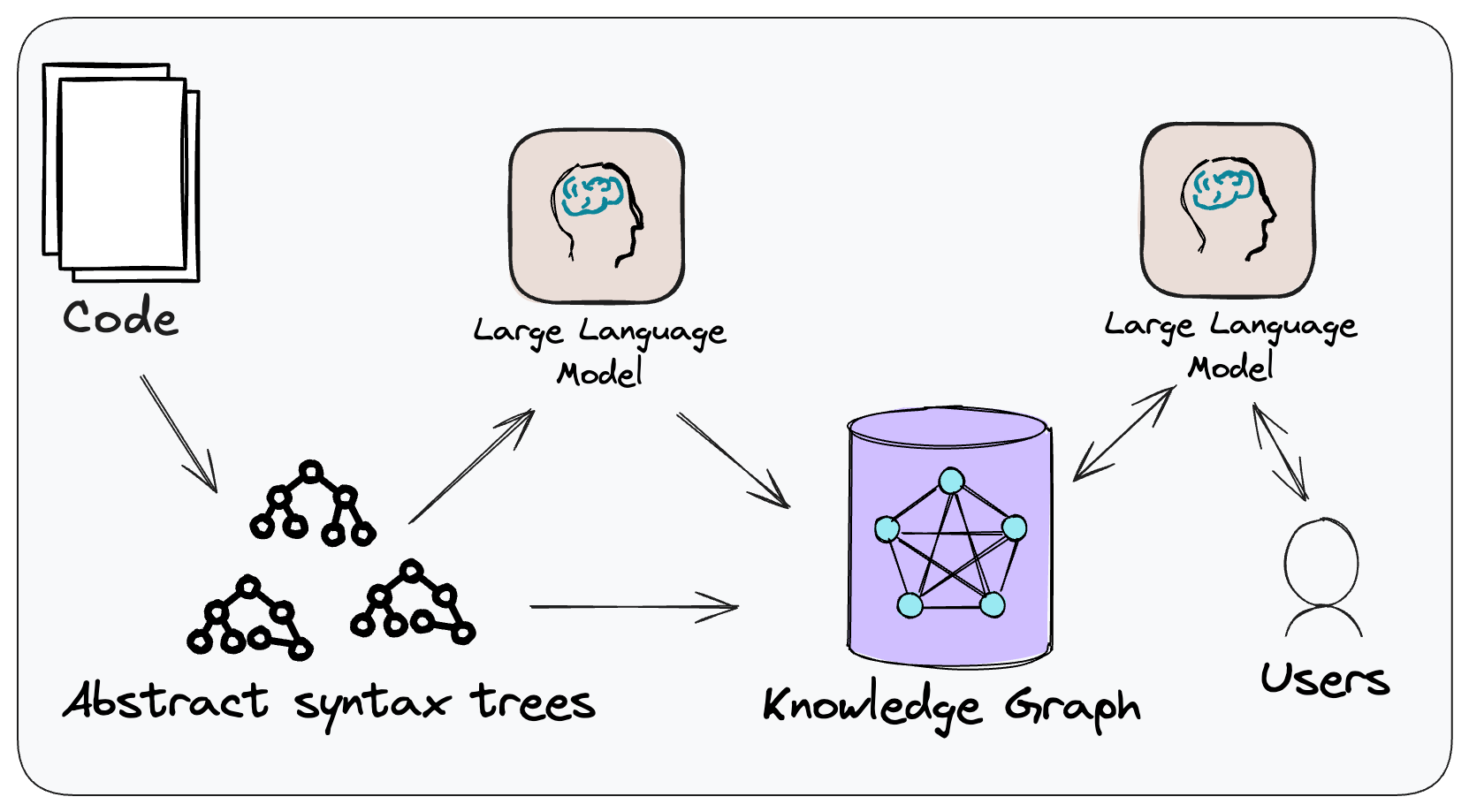
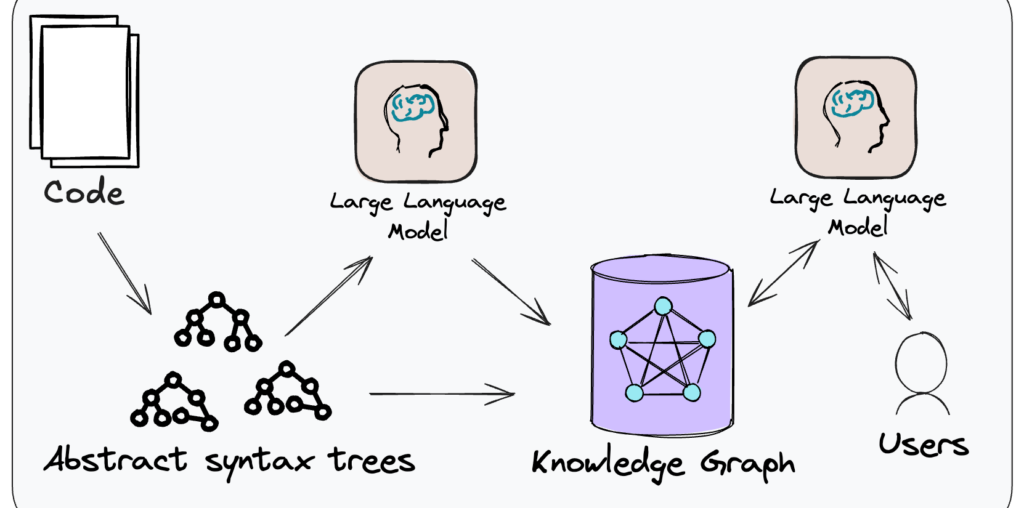
Figure 1: The conceptual approach of CodeConcise.
CodeConcise is inspired by the Code-as-data
concept, where code is
treated and analyzed in ways traditionally reserved for data. This means
we are not treating code just as text, but through employing language
specific parsers, we can extract its intrinsic structure, and map the
relationships between entities in the code. This is done by parsing the
code into a forest of Abstract Syntax Trees (ASTs), which are then
stored in a graph database.

Figure 2: An ingestion pipeline in CodeConcise.
Edges between nodes are then established, for example an edge might be saying
“the code in this node transfers control to the code in that node”. This process
does not only allow us to understand how one file in the codebase might relate
to another, but we also extract at a much granular level, for example, which
conditional branch of the code in one file transfers control to code in the
other file. The ability to traverse the codebase at such a level of granularity
is particularly important as it reduces noise (i.e. unnecessary code) from the
context provided to LLMs, especially relevant for files that do not contain
highly cohesive code. Primarily, there are two benefits we observe from this
noise reduction. First, the LLM is more likely to stay focussed on the prompt.
Second, we use the limited space in the context window in an efficient way so we
can fit more information into one single prompt. Effectively, this allows the
LLM to analyze code in a way that is not limited by how the code is organized in
the first place by developers. We refer to this deterministic process as the ingestion pipeline.
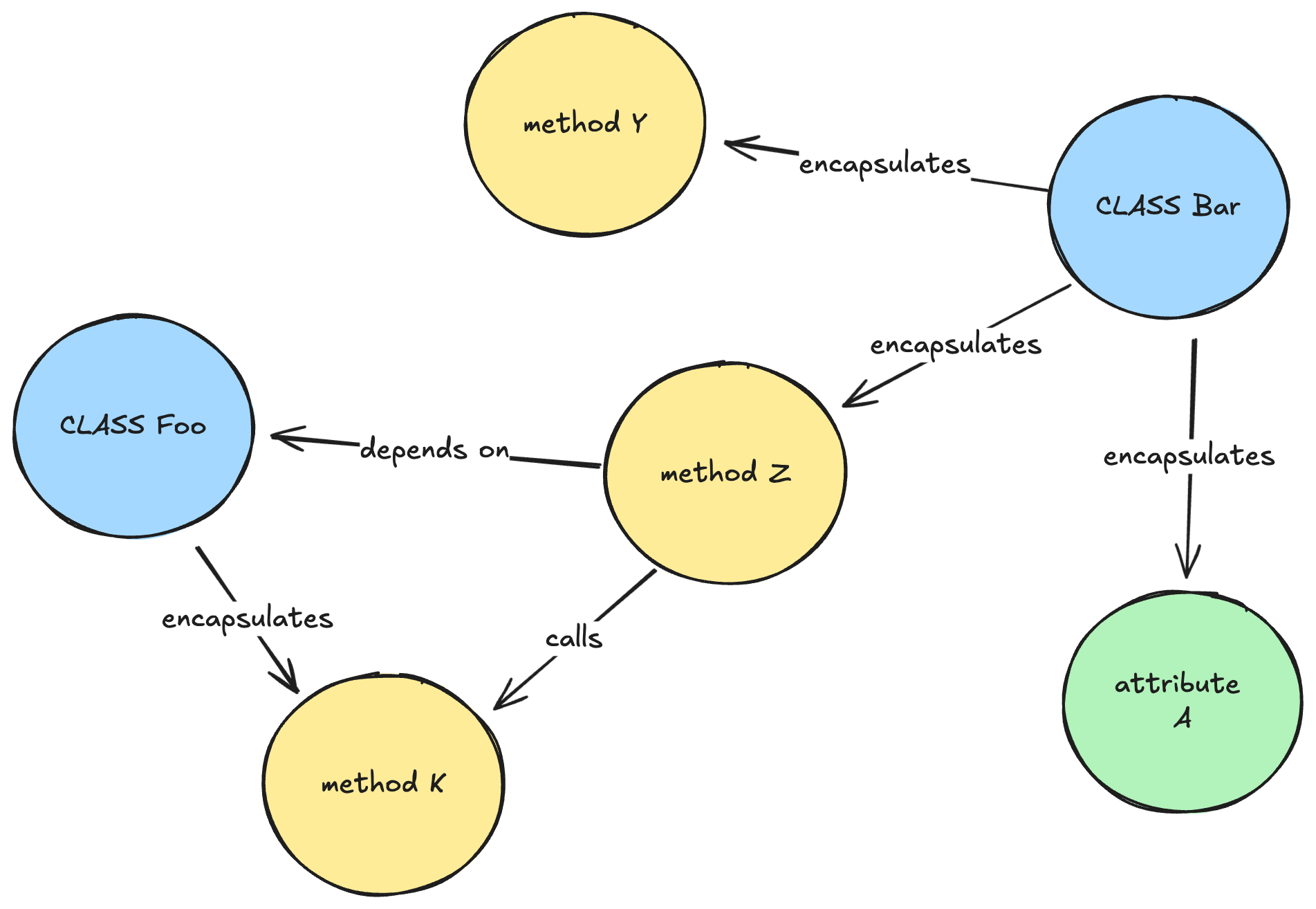
Figure 3: A simplified representation of how a knowledge graph might look like for a Java codebase.
Subsequently, a comprehension pipeline traverses the graph using multiple
algorithms, such as Depth-first Search with
backtracking in post-order
traversal, to enrich the graph with LLM-generated explanations at various depths
(e.g. methods, classes, packages). While some approaches at this stage are
common across legacy tech stacks, we have also engineered prompts in our
comprehension pipeline tailored to specific languages or frameworks. As we began
using CodeConcise with real, production client code, we recognised the need to
keep the comprehension pipeline extensible. This ensures we can extract the
knowledge most valuable to our users, considering their specific domain context.
For example, at one client, we discovered that a query to a specific database
table implemented in code would be better understood by Business Analysts if
described using our client’s business terminology. This is particularly relevant
when there is not a Ubiquitous
Language shared between
technical and business teams. While the (enriched) knowledge graph is the main
product of the comprehension pipeline, it is not the only valuable one. Some
enrichments produced during the pipeline, such as automatically generated
documentation about the system, are valuable on their own. When provided
directly to users, these enrichments can complement or fill gaps in existing
systems documentation, if one exists.
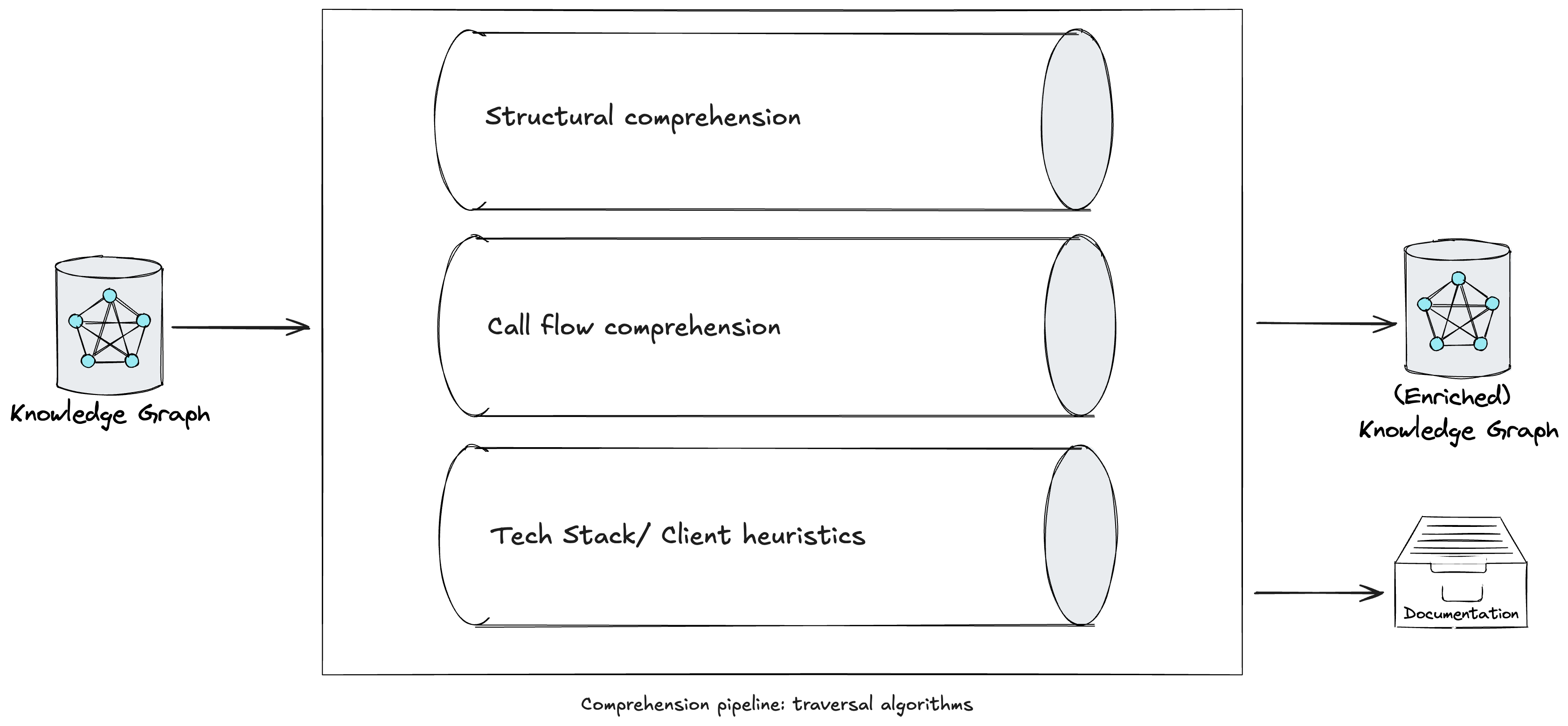
Figure 4: A comprehension pipeline in CodeConcise.
Neo4j, our graph database of choice, holds the (enriched) Knowledge Graph.
This DBMS features vector search capabilities, enabling us to integrate the
Knowledge Graph into the frontend application implementing RAG. This approach
provides the LLM with a much richer context by leveraging the graph’s structure,
allowing it to traverse neighboring nodes and access LLM-generated explanations
at various levels of abstraction. In other words, the retrieval component of RAG
pulls nodes relevant to the user’s prompt, while the LLM further traverses the
graph to gather more information from their neighboring nodes. For instance,
when looking for information relevant to a query about “how does authorization
work when viewing card details?” the index may only provide back results that
explicitly deal with validating user roles, and the direct code that does so.
However, with both behavioral and structural edges in the graph, we can also
include relevant information in called methods, the surrounding package of code,
and in the data structures that have been passed into the code when providing
context to the LLM, thus provoking a better answer. The following is an example
of an enriched knowledge graph for AWS Card
Demo,
where blue and green nodes are the outputs of the enrichments executed in the
comprehension pipeline.

Figure 5: An (enriched) knowledge graph for AWS Card Demo.
The relevance of the context provided by further traversing the graph
ultimately depends on the criteria used to construct and enrich the graph in the
first place. There is no one-size-fits-all solution for this; it will depend on
the specific context, the insights one aims to extract from their code, and,
ultimately, on the principles and approaches that the development teams followed
when constructing the solution’s codebase. For instance, heavy use of
inheritance structures might require more emphasis on INHERITS_FROM edges vs
COMPOSED_OF edges in a codebase that favors composition.
For further details on the CodeConcise solution model, and insights into the
progressive learning we had through the 3 iterations of the accelerator, we
will soon be publishing another article: Code comprehension experiments with
LLMs.
In the subsequent sections, we delve deeper into specific modernization
challenges that, if solved using GenAI, could significantly impact the cost,
value, and time for modernization – factors that often discourage us from making
the decision to modernize now. In some cases, we have begun exploring internally
how GenAI might address challenges we have not yet had the opportunity to
experiment with alongside our clients. Where this is the case, our writing is
more speculative, and we have highlighted these instances accordingly.
Reverse engineering: drawing out low-level requirements
When undertaking a legacy modernization journey and following a path
like Rewrite or Replace, we have learned that, in order to draw a
comprehensive list of requirements for our target system, we need to
examine the source code of the legacy system and perform reverse
engineering. These will guide your forward engineering teams. Not all
these requirements will necessarily be incorporated into the target
system, especially for systems developed over many years, some of which
may no longer be relevant in today’s business and market context.
However, it is crucial to understand existing behavior to make informed
decisions about what to retain, discard, and introduce in your new
system.
The process of reverse engineering a legacy codebase can be time
consuming and requires expertise from both technical and business
people. Let us consider below some of the activities we perform to gain
a comprehensive low-level understanding of the requirements, including
how GenAI can help enhance the process.
Manual code reviews
Encompassing both static and dynamic code analysis. Static
analysis involves reviewing the source code directly, sometimes
aided by specific tools for a given technical stack. These aim to
extract insights such as dependency diagrams, CRUD (Create Read
Update Delete) reports for the persistence layer, and low-level
program flowcharts. Dynamic code analysis, on the other hand,
focuses on the runtime behavior of the code. It is particularly
useful when a section of the code can be executed in a controlled
environment to observe its behavior. Analyzing logs produced during
runtime can also provide valuable insights into the system’s
behavior and its components. GenAI can significantly enhance
the understanding and explanation of code through code reviews,
especially for engineers unfamiliar with a particular tech stack,
which is often the case with legacy systems. We believe this
capability is invaluable to engineering teams, as it reduces the
often inevitable dependency on a limited number of experts in a
specific stack. At one client, we have leveraged CodeConcise,
utilizing an LLM to extract low-level requirements from the code. We
have extended the comprehension pipeline to produce static reports
containing the information Business Analysts (BAs) needed to
effectively derive requirements from the code, demonstrating how
GenAI can empower non-technical people to be involved in
this specific use case.
Abstracted program flowcharts
Low-level program flowcharts can obscure the overall intent of
the code and overwhelm BAs with excessive technical details.
Therefore, collaboration between reverse engineers and Subject
Matter Experts (SMEs) is crucial. This collaboration aims to create
abstracted versions of program flowcharts that preserve the
essential flows and intentions of the code. These visual artifacts
aid BAs in harvesting requirements for forward engineering. We have
learnt with our client that we could employ GenAI to produce
abstract flowcharts for each module in the system. While it may be
cheaper to manually produce an abstract flowchart at a system level,
doing so for each module(~10,000 lines of code, with a total of 1500
modules) would be very inefficient. With GenAI, we were able to
provide BAs with visual abstractions that revealed the intentions of
the code, while removing most of the technical jargon.
SME validation
SMEs are consulted at multiple stages during the reverse
engineering process by both developers and BAs. Their combined
technical and business expertise is used to validate the
understanding of specific parts of the system and the artifacts
produced during the process, as well as to clarify any outstanding
queries. Their business and technical expertise, developed over many
years, makes them a scarce resource within organizations. Often,
they are stretched too thin across multiple teams just to “keep
the lights on”. This presents an opportunity for GenAI
to reduce dependencies on SMEs. At our client, we experimented with
the chatbot featured in CodeConcise, which allows BAs to clarify
uncertainties or request additional information. This chatbot, as
previously described, leverages LLM and Knowledge Graph technologies
to provide answers similar to those an SME would offer, helping to
mitigate the time constraints BAs face when working with them.
Thoughtworks worked with the client mentioned earlier to explore ways to
accelerate the reverse engineering of a large legacy codebase written in COBOL/
IDMS. To achieve this, we extended CodeConcise to support the client’s tech
stack and developed a proof of concept (PoC) utilizing the accelerator in the
manner described above. Before the PoC, reverse engineering 10,000 lines of code
typically took 6 weeks (2 FTEs working for 4 weeks, plus wait time and an SME
review). At the end of the PoC, we estimated that our solution could reduce this
by two-thirds, from 6 weeks to 2 weeks for a module. This translates to a
potential saving of 240 FTE years for the entire mainframe modernization
program.
High-level, abstract explanation of a system
We have experienced that LLMs can help us understand low-level
requirements more quickly. The next question is whether they can also
help us with high-level requirements. At this level, there is much
information to take in and it is tough to digest it all. To tackle this,
we create mental models which serve as abstractions that provide a
conceptual, manageable, and comprehensible view of the applications we
are looking into. Usually, these models exist only in people’s heads.
Our approach involves working closely with experts, both technical and
business focussed, early on in the project. We hold workshops, such as
Event
Storming
from Domain-driven Design, to extract SMEs’ mental models and store them
on digital boards for visibility, continuous evolution, and
collaboration. These models contain a domain language understood by both
business and technical people, fostering a shared understanding of a
complex domain among all team members. At a higher level of abstraction,
these models may also describe integrations with external systems, which
can be either internal or external to the organization.
It is becoming evident that access to, and availability of SMEs is
essential for understanding complex legacy systems at an abstract level
in a cost-effective manner. Many of the constraints previously
highlighted are therefore applicable to this modernization
challenge.
In the era of GenAI, specifically in the modernization space, we are
seeing good outputs from LLMs when they are prompted to explain a small
subset of legacy code. Now, we want to explore whether LLMs can be as
useful in explaining a system at a higher level of abstraction.
Our accelerator, CodeConcise, builds upon Code as Data techniques by
utilizing the graph representation of a legacy system codebase to
generate LLM-generated explanations of code and concepts at different
levels of abstraction:
- Graph traversal strategy: We leverage the entire codebase’s
representation as a graph and use traversal algorithms to enrich the graph with
LLM-generated explanations at various depths. - Contextual knowledge: Beyond processing the code and storing it in the
graph, we are exploring ways to process any available system documentation, as
it often provides valuable insights into business terminology, processes, and
rules, assuming it is of good quality. By connecting this contextual
documentation to code nodes on the graph, our hypothesis is we can enhance
further the context available to LLMs during both upfront code explanation and
when retrieving information in response to user queries.
Ultimately, the goal is to enhance CodeConcise’s understanding of the
code with more abstract concepts, enabling its chatbot interface to
answer questions that typically require an SME, keeping in mind that
such questions might not be directly answerable by examining the code
alone.
At Thoughtworks, we are observing positive outcomes in both
traversing the graph and generating LLM explanations at various levels
of code abstraction. We have analyzed an open-source COBOL repository,
AWS Card
Demo,
and successfully asked high-level questions such as detailing the system
features and user interactions. In this occasion, the codebase included
documentation, which provided additional contextual knowledge for the
LLM. This enabled the LLM to generate higher-quality answers to our
questions. Additionally, our GenAI-powered team assistant, Haiven, has
demonstrated at multiple clients how contextual information about a
system can enable an LLM to provide answers tailored to
the specific client context.
Discovering a capability map of a system
One of the first things we do when beginning a modernization journey
is catalog existing technology, processes, and the people who support
them. Within this process, we also define the scope of what will be
modernized. By assembling and agreeing on these elements, we can build a
strong business case for the change, develop the technology and business
roadmaps, and consider the organizational implications.
Without having this at hand, there is no way to determine what needs
to be included, what the plan to achieve is, the incremental steps to
take, and when we are done.
Before GenAI, our teams have been using a number of
techniques to build this understanding, when it is not already present.
These techniques range from Event Storming and Process Mapping through
to “following the data” through the system, and even targeted code
reviews for particularly complex subdomains. By combining these
approaches, we can assemble a capability map of our clients’
landscapes.
While this may appear like a large amount of manual effort, these can
be some of the most valuable activities as it not only builds a plan for
the future delivery, but the thinking and collaboration that goes into
making it ensures alignment of the involved stakeholders, especially
around what is going to be included or excluded from the modernization
scope. Also, we have learnt that capability maps are invaluable when we
take a capability-driven approach to modernization. This helps modernize
the legacy system incrementally by gradually delivering capabilities in
the target system, in addition to designing an architecture where
concerns are cleanly separated.
GenAI changes this picture a lot.
One of the most powerful capabilities that GenAI brings is
the ability to summarize large volumes of text and other media. We can
use this capability across existing documentation that may be present
regarding technology or processes to extract out, if not the end
knowledge, then at least a starting point for further conversations.
There are a number of techniques that are being actively developed and
released in this area. In particular, we believe that
GraphRAG which was recently
released by Microsoft could be used to extract a level of knowledge from
these documents through Graph Algorithm analysis of the body of
text.
We have also been trialing GenAI over the top of the knowledge graph
that we build out of the legacy code as mentioned earlier by asking what
key capabilities modules have and then clustering and abstracting these
through hierarchical summarization. This then serves as a map of
capabilities, expressed succinctly at both a very high level and a
detailed level, where each capability is linked to the source code
modules where it is implemented. This is then used to scope and plan for
the modernization in a faster manner. The following is an example of a
capability map for a system, including the source code modules (small
gray nodes) they are implemented in.
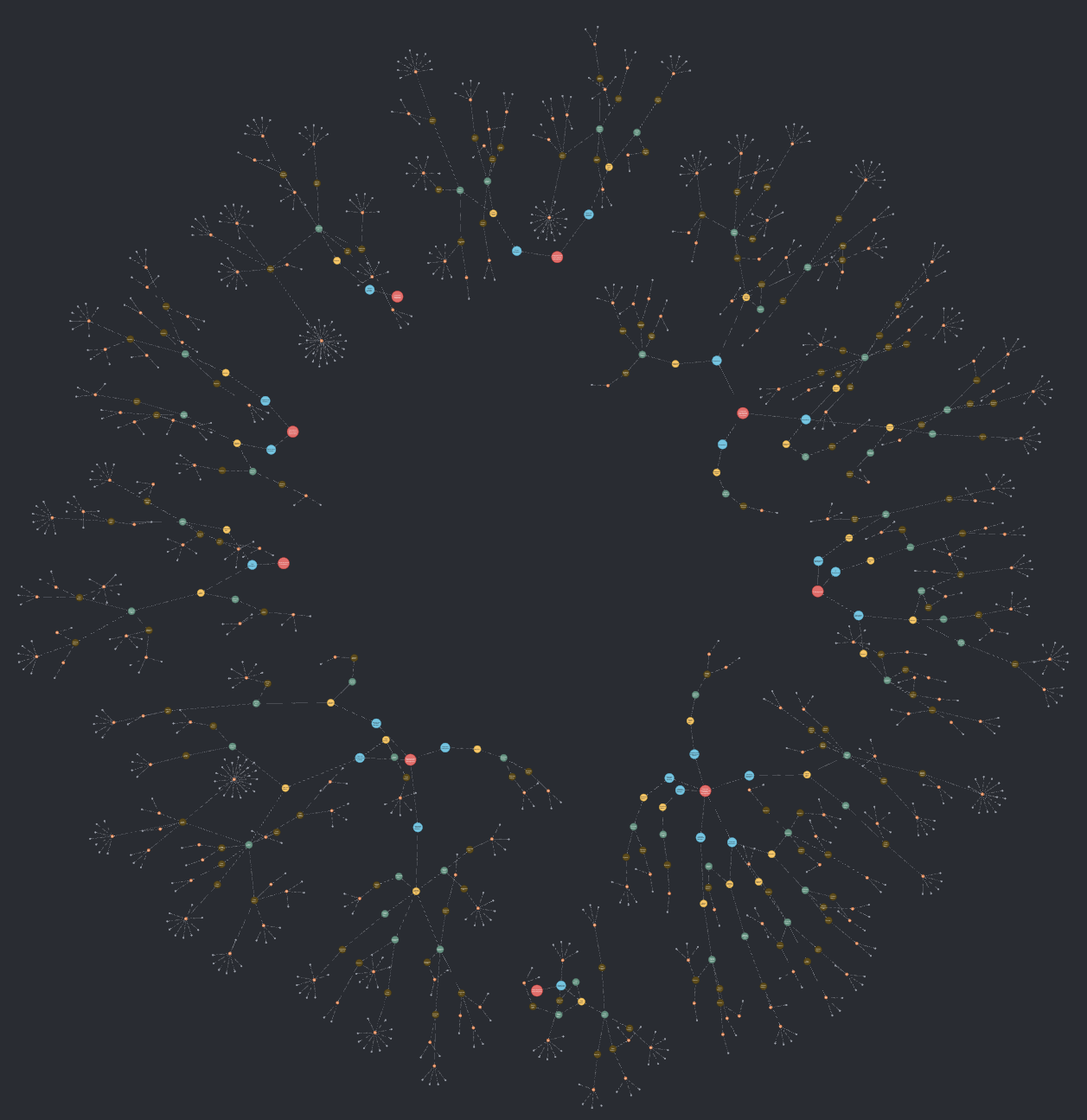
Nevertheless, we have learnt not to view this entirely LLM-generated
capability map as mutually exclusive from the traditional methods of
creating capability maps described earlier. These traditional approaches
are valuable not only for aligning stakeholders on the scope of
modernization, but also because, when a capability already exists, it
can be used to cluster the source code based on the capabilities
implemented. This approach produces capability maps that resonate better
with SMEs by using the organization’s Ubiquitous language. Additionally,
comparing both capability maps might be a valuable exercise, surely one
we look forward to experimenting with, as each might offer insights the
other does not.
Discovering unused / dead / duplicate code
Another part of gathering information for your modernization efforts
is understanding within your scope of work, “what is still being used at
all”, or “where have we got multiple instances of the same
capability”.
Currently this can be addressed quite effectively by combining two
approaches: static and dynamic analysis. Static analysis can find unused
method calls and statements within certain scopes of interrogation, for
instance, finding unused methods in a Java class, or finding unreachable
paragraphs in COBOL. However, it is unable to determine whether whole
API endpoints or batch jobs are used or not.
This is where we use dynamic analysis which leverages system
observability and other runtime information to determine if these
functions are still in use, or can be dropped from our modernization
backlog.
When looking to find duplicate technical capabilities, static
analysis is the most commonly used tool as it can do chunk-by-chunk text
similarity checks. However, there are major shortcomings when applied to
even a modest technology estate: we can only find code similarities in
the same language.
We speculate that by leveraging the result of our capability
extraction approach, we can use these technology agnostic descriptions
of what large and small abstractions of the code are doing to perform an
estate-wide analysis of duplication, which will take our future
architecture and roadmap planning to the next level.
When it comes to unused code however, we see little or no use in
applying GenAI to the problem. Static analysis tools in the industry for
finding dead code are very mature, leverage the structured nature of
code and are already at developers’ fingertips, like IntelliJ or Sonar.
Dynamic analysis from APM tools is so powerful there’s little that tools
like GenAI can add to the extraction of information itself.
On the other hand, these two complex approaches can yield a vast
amount of data to understand, interrogate and derive insight from. This
could be one area where GenAI could provide a minor acceleration
for discovery of little used code and technology.
Similar to having GenAI refer to large reams of product documentation
or specifications, we can leverage its knowledge of the static and
dynamic tools to help us use them in the right way for instance by
suggesting potential queries that can be run over observability stacks.
NewRelic, for instance, claims to have integrated LLMs in to its solutions to
accelerate onboarding and error resolution; this could be turned to a
modernization advantage too.
Idiomatic translation of tech paradigm
Translation from one programming language to another is not something new. Most of the tools that do this have
applied static analysis techniques – using Abstract Syntax Trees (ASTs) as intermediaries.
Although these techniques and tools have existed for a long time, results are often poor when judged through
the lens of “would someone have written it like this if they had started authoring it today”.
Typically the produced code suffers from:
Poor overall Code quality
Usually, the code these tools produce is syntactically correct, but leaves a lot to be desired regarding
quality. A lot of this can be attributed to the algorithmic translation approach that is used.
Non-idiomatic code
Typically, the code produced does not match idiomatic paradigms of the target technology stack.
Poor naming conventions
Naming is as good or bad as it was in the source language/ tech stack – and even when naming is good in the
older code, it does not translate well to newer code. Imagine automatically naming classes/ objects/ methods
when translating procedural code that transfers files to an OO paradigm!
Isolation from open-source libraries/ frameworks
- Modern applications typically use many open-source libraries and frameworks (as opposed to older
languages) – and generating code at most times does not seamlessly do the same - This is even more complicated in enterprise settings when organizations tend to have internal libraries
(that tools will not be familiar with)
Loss of precision in data
Even with primitive types languages have different precisions – which is likely to lead to a loss in
precision.
Loss in relevance of source code history
Many times when trying to understand code we look at how that code evolved to that state with git log [or
equivalents for other SCMs] – but now that history is not beneficial for the same purpose
Assuming an organization embarks on this journey, it will soon face lengthy testing and verification
cycles to ensure the generated code behaves exactly the same way as before. This becomes even more challenging
when little to no safety net was in place initially.
Despite all the drawbacks, code conversion approaches continue to be an option that attracts some organizations
because of their allure as potentially the lowest cost/ effort solution for leapfrogging from one tech paradigm
to the other.
We have also been thinking about this and exploring how GenAI can help improve the code produced/ generated. It
can’t help all of those issues, but maybe it can help alleviate at least the first three or four of them.
From an approach perspective, we are trying to apply the principles of
Refactoring
to this – essentially
figure out a way we can safely and incrementally make the jump from one tech paradigm to another. This approach
has already seen some success – two examples that come to mind:
Conclusion
Today’s landscape has numerous opportunities to leverage GenAI to
achieve outcomes that were previously out of reach. In the software
industry, GenAI is already playing a significant role in helping people
across various roles complete their tasks more efficiently, and this
impact is expected to grow. For instance, GenAI has produced promising
results in assisting technical engineers with writing code.
Over the past decades, our industry has evolved significantly, developing patterns, best practices, and
methodologies that guide us in building modern software. However, one of the biggest challenges we now face is
updating the vast amount of code that supports key operations daily. These systems are often large and complex,
with multiple layers and patches built over time, making behavior difficult to change. Additionally, there are
often only a few experts who fully understand the intricate details of how these systems are implemented and
operate. For these reasons, we use an evolutionary approach to legacy displacement, reducing the risks involved
in modernizing these systems and producing value early. Despite this, the cost/time/value equation for
modernizing large systems is often prohibitive. In this article, we discussed ways GenAI can be harnessed to
turn this situation around. We will continue experimenting with applying GenAI to these modernization challenges
and share our insights through this article, which we will keep up to date. This will include sharing what has
worked, what we believe GenAI could potentially solve, and what, however, has not succeeded. Additionally, we
will extend our accelerator, CodeConcise, with the aim of further innovating within the modernization process to
drive greater value for our clients.
Hopefully, this article highlights the great potential of harnessing
this new technology, GenAI, to address some of the challenges posed by
legacy systems in the industry. While there is no one-size-fits-all
solution to these challenges – each context has its own unique nuances –
there are often similarities that can guide our efforts. We also hope this
article inspires others in the industry to further develop experiments
with “GenAI for Modernization” and share their insights with the broader
community.