

Introduction
The Feature Systems team at Etsy is responsible for the platform and services through which machine learning (ML) practitioners create, manage and consume feature data for their machine learning models. We recently made new real-time features available through our streaming feature platform, Rivulet, where we return things like “most recent add-to-carts.” While timeseries data itself wasn’t new to our system, these newer features from our streaming feature service would be the first timeseries inputs to be supplied to our ML models themselves to inform search, ads, and recommendations use cases.
Not too long after we made these features available to users for ML model training, we received a message from Harshal, an ML practitioner on Recommendations, warning us of “major problems” lying in wait.
 Figure 1. A user message alerting us to the possibility of “major problems for downstream ML models” in our use of the timestamp datatype.
Figure 1. A user message alerting us to the possibility of “major problems for downstream ML models” in our use of the timestamp datatype.
Harshal told us our choice to export real-time features using a timestamp datatype was going to cause problems in downstream models.
The training data that comes from our offline feature store uses the binary Avro file format, which has a logical type called timestamp we used to store these features, with an annotation specifying that they should be at the millisecond precision. The problem, we were being informed, is that this Avro logical type would be interpreted differently in different frameworks. Pandas, NumPy, and Spark would read our timestamps, served with millisecond precision, as datetime objects with nanosecond precision – creating the possibility of a training/serving skew. In order to prevent mismatches, and the risk they posed of silent failures in production, the recommendation was that we avoid the timestamp type entirely and serve our features as a more basic numeric data type, such as Longs.
Getting to the root of the issue
We started the way software engineers usually do, attempting to break down the problem and get to root causes. Before changing data types, we wanted to understand if the misinterpretation of the precision of the timestamp was an issue with Python, Spark, or even a misuse of the Avro timestamp annotation that we were using to specify the millisecond precision. We were hesitant to alter the data type of the feature without an in-depth investigation. After all, timestamp and datetime objects are typically passed around between systems precisely to resolve inconsistencies and improve communication.
We started by attempting to put together a diagram of all the different ways that timestamp features were represented across our systems. The result was a diagram like this:
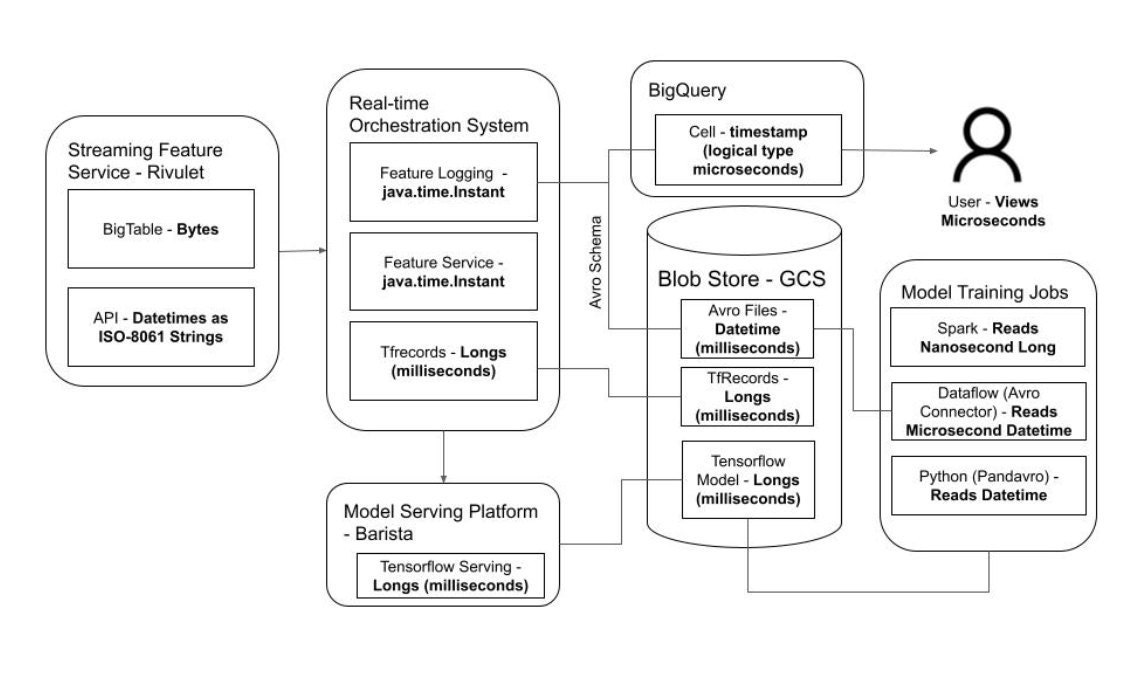 Figure 2. A diagram of all the objects/interpretations of timestamp features across our systems. Though the user only ever sees microseconds, between system domains we see a diversity of representations.
Figure 2. A diagram of all the objects/interpretations of timestamp features across our systems. Though the user only ever sees microseconds, between system domains we see a diversity of representations.
While it was clear Spark and other frameworks weren’t respecting the timestamp annotation that specified millisecond precision, we began to realize that that problem was actually a symptom of a larger issue for our ML practitioners. Timestamp features can take a number of different forms before finally being passed into a model. In itself this isn’t really surprising. Every type is language-specific in one way or another – the diagram would look similar if we were going to be serializing integers in Scala and deserializing integers in Python. However, the overall disparity between objects is much greater for complex datetime objects than it is for basic data types. There is simply more room for interpretation with datetime objects, and less certainty about how they translate across system boundaries, and for our use case in training ML models uncertainty was exactly what we did not want.
As we dug deeper into the question, it started to become clear that we weren’t trying to resolve a specific bug or issue, but reduce the amount of toil for ML practitioners who would be consuming timestamp features long-term. While the ISO-8061 format is massively helpful for sharing datetime and timestamp objects across different systems, it’s less helpful when all you’re looking for is an integer representation at a specific precision.
Since these timestamps were features of a machine learning model, we didn’t need all the complexity that datetime objects and timestamp types offered across systems. The use case for this information was to be fed as an integer of a specific precision into an ML model, and nothing more. Storing timestamps as logical types increased cognitive overhead for ML practitioners and introduced additional risk that training with the wrong precision could degrade model quality during inference.
Takeaways
This small request bubbled into a much larger discussion during one of our organization’s architecture working group meetings. Although folks were initially hesitant to change the type of these features, by the end of the meeting there was a broad consensus that it would be desirable to represent datetime features in our system as a primitive numeric type (unix timestamps with millisecond precision) to promote consistency between model training and inference.
Given the wide range of training contexts that all of our features are used in, we decided it was a good idea to promote consistency between training and inference by standardizing on primitive types more generally. Members of the Feature Systems team also expressed a desire to improve documentation around how features are transformed end-to-end throughout the current system to make things easier for customers in the future.
We designed our ML features with abstraction and interoperability in mind, as software engineers do. It’s not that ML isn’t a software engineering practice, but that it’s a domain in which the specific needs of ML software didn’t match our mental model of best practices for the system. Although ML has been around for some time, the rapidly-changing nature of the space means the nuance of many ML-specific guidelines are still ill-defined. I imagine this small cross-section of difficulty applying software practices to ML practices will be the first of many as ML continues its trajectory through software systems of all shapes and sizes.