

- Cryptographic monitoring at scale has been instrumental in helping our engineers understand how cryptography is used at Meta.
- Monitoring has given us a distinct advantage in our efforts to proactively detect and remove weak cryptographic algorithms and has assisted with our general change safety and reliability efforts.
- We’re sharing insights into our own cryptographic monitoring system, including challenges faced in its implementation, with the hope of assisting others in the industry aiming to deploy cryptographic monitoring at a similar scale.
Meta’s managed cryptographic library, FBCrypto, plays an important role within Meta’s infrastructure and is used by the majority of our core infrastructure services. Given this, having a robust monitoring system in place for FBCrypto has been instrumental in ensuring its reliability as well as in helping our engineers understand how cryptography is used at Meta so they can make informed development decisions.
Monitoring the health of our library allows us to detect and revert bugs before they reach production services. The data from our monitoring service provides insight into the usage of FBCrypto, allowing us to make data-driven decisions when deciding what improvements to make to the library. For example, it helps us identify components that need more attention either because they are on a hot path or are less stable.
Understanding exactly how clients are using said library is a common pain point in managing any widely distributed library. But the improved understanding of FBCrypto provided by our monitoring helps us maintain a high bar for security posture. Since there is a limit to how much data a symmetric cryptographic key can protect, logging allows us to detect key overuse and rotate keys proactively. It also helps us build an inventory of cryptography usage, making it easy to identify the callsites of weakened algorithms that need to be migrated – a very important task because we need to proactively switch from weakened algorithms to newer, more robust ones as cryptography strength decays over time.
More generally, improved understanding helps us to make emergency algorithm migrations when a vulnerability of a primitive is discovered.
More recently, this is aiding our efforts to ensure post-quantum readiness in our asymmetric use cases. The available data improves our decision-making process while prioritizing quantum-vulnerable use cases
How cryptographic monitoring works at Meta
Effective cryptographic monitoring requires storing persisted logs of cryptographic events, upon which diagnostic and analytic tools can be used to gather further insights. Supporting logging at the scale of FBCrypto requires an implementation with unique performance considerations in mind. Given that FBCrypto is used along many high-volume and critical code paths, a naive logging implementation could easily overwhelm a standard logging infrastructure or cause significant performance regressions. This is true for most widely distributed libraries and is especially true in the field of cryptography, where the sheer volume of usage can come as a complete surprise to those unfamiliar with the space. For example, we recently disclosed that roughly 0.05% of CPU cycles at Meta are spent on X25519 key exchange.
Most of Meta’s logs are constructed and written via Scribe, Meta’s standard logging framework. From there, data persists in Scuba and Hive, Meta’s short-term and long term data stores, respectively.
Typically, the Scribe API is called directly to construct a log for every “event” that needs to be logged. For FBCrypto, this would mean constructing a log for nearly every cryptographic operation that our library is used for. Unfortunately, given the sheer frequency of such operations, a solution like this would consume an unreasonable amount of write throughput and storage capacity. A common solution to this problem would be to introduce sampling (i.e., only log 1/X cryptographic operations, and increase X until we no longer have capacity concerns). However, we felt strongly about not introducing any sampling since doing so would result in most logs being omitted, giving us a less clear picture of the library’s usage.
Instead, the logging uses a “buffering and flushing” strategy, in which cryptographic events are aggregated across time and flushed to a data store at a preconfigured interval.
During the aggregation, a “count” is maintained for every unique event. When it comes time to flush, this count is exported along with the log to convey how often that particular event took place.
Below is a rough illustration of what this looks like:
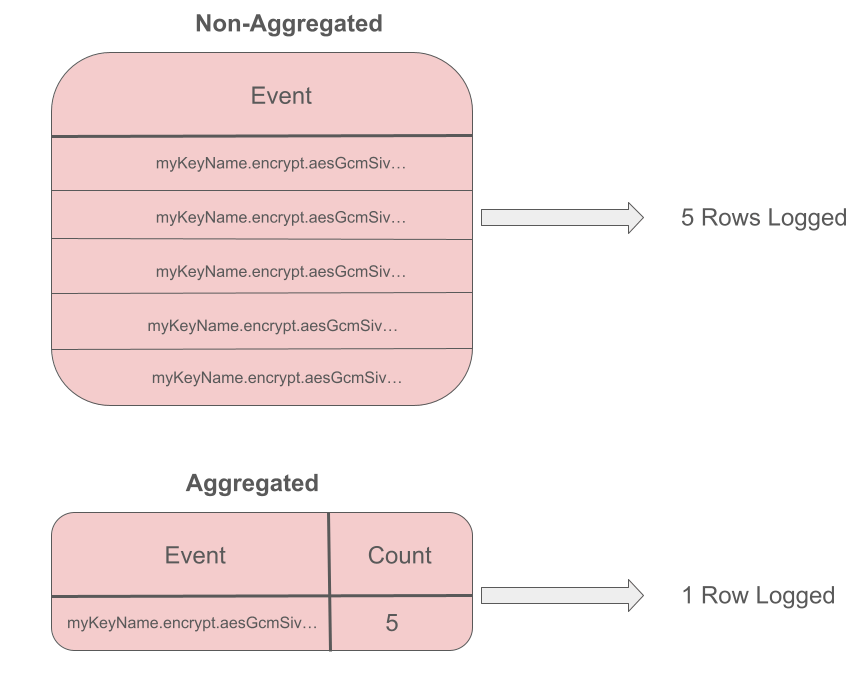
In the above example, the key named “myKeyName” is used to perform encryption using the AES-GCM-SIV encryption algorithm (in practice we log more fields than just key name, method, and algorithm). The operation happens five times and is assigned on a count of five. Since machines often compute millions of cryptographic operations per day, this strategy can lead to significant compute savings in production.
A client-side view
The aggregation and flushing is implemented within FBCrypto, so the logging and flushing code sits on the client hosts. When clients call a given cryptographic operation (e.g., “encrypt()”), the operation is performed and the log is added to our aggregated buffer. We refer to the object that holds the buffer as the “buffered logger.”
Note that the logging does not change the interface of FBCrypto, so all of this is transparent to the clients of the library.
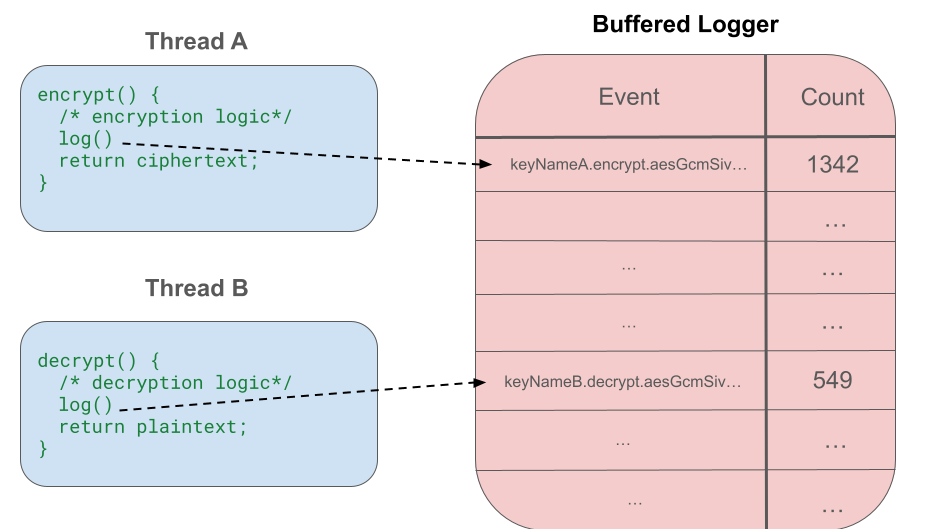
In multithreaded environments all threads will log to the same buffer. For this to be performant, we need to choose the right underlying data structure (see the section below on “Additional optimizations” for more details).
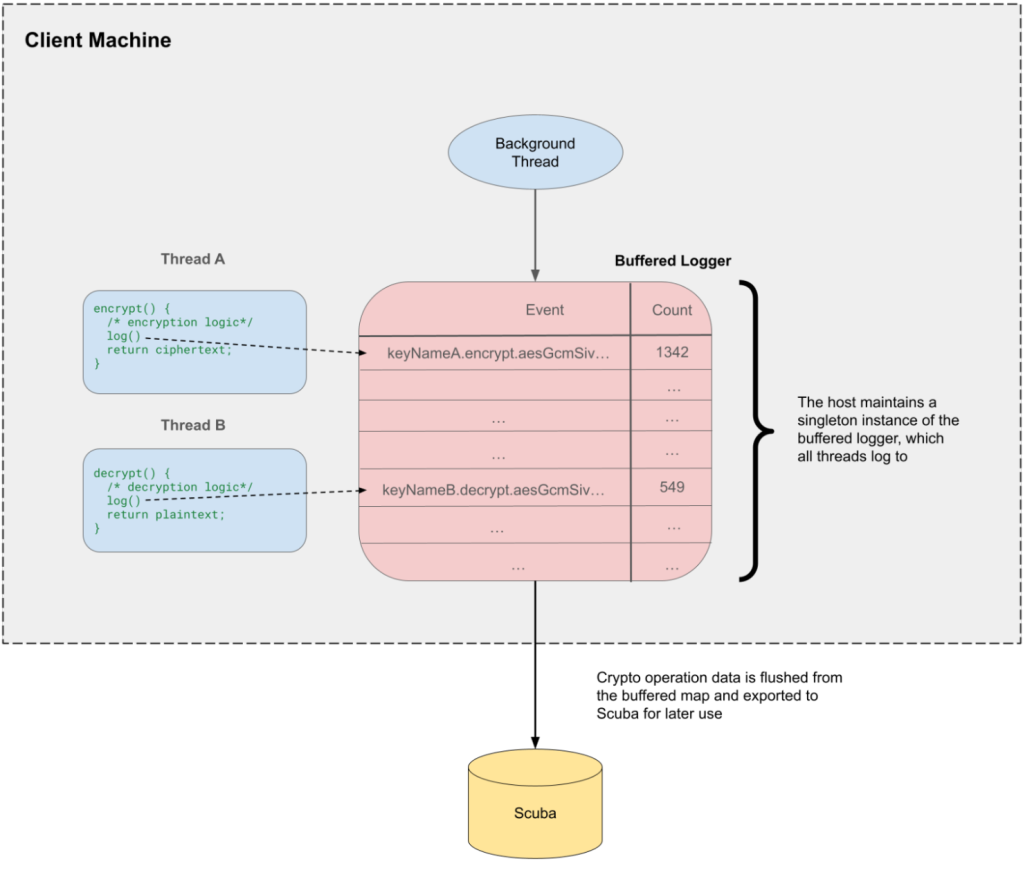
While the aggregation works to reduce space and time overhead, the logs need to eventually be written to storage for further use. To do this, a background thread runs on the client host to periodically call the Scribe API to export the logs and flush the map’s contents.
Below is an overview of the overall flow:
Additional optimizations
We had to make some additional optimizations to support cryptographic monitoring on Meta’s major products (Facebook, Whatsapp, Instagram, etc.).
With careful design choices around the logging logic and data structures used, our cryptographic logging operates with no sampling and has had a negligible impact on compute performance across Meta’s fleet.
Partially randomized flushing
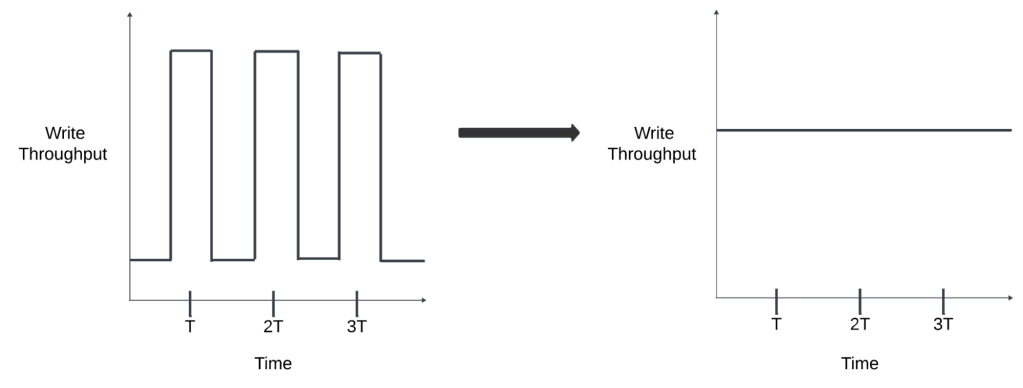
Due to the nature of our buffering and flushing strategy, certain clients who were running jobs that restarted large sets of machines at around the same time would have those machines’ logs get flushed at about the same time. This would result in “spiky” writes to the logging platform, followed by longer periods of underutilization between flushes. To normalize our write throughput, we distribute these spikes across time by applying a randomized delay on a per-host basis before logs are flushed for the first time. This leads to a more uniform flushing cadence, allowing for a more consistent load on Scribe.
The figure below demonstrates how this works:
Derived crypto
FBCrypto supports a feature called derived crypto, which allows “child” keysets to be derived from “parent” keysets by applying a key derivation function (KDF) to all the keys in the keyset with some salt. This feature is used by a few large-scale use cases that need to generate millions of keys.
Our logging initially created a unique row in the buffered logger for every derived keyset, which used a lot of space and put increased load on backend data stores. To address this, we now aggregate the cryptographic operations of derived keys under the name of the parent key. This reduces our overall capacity needs without harming our ability to detect key overuse since, in the worst case, the aggregations would be a pessimistic counter for any given child key.
Thanks to this aggregation, we were able to cut down on the vast majority of our logging volume, compared to the space that would have been used with no aggregation.
The Folly library
Internally, our buffering makes use of the folly::ConcurrentHashMap, which is built to be performant under heavy writes in multithreaded environments, while still guaranteeing atomic accesses.
Unified offerings
Meta’s existing infrastructure and its emphasis on unified offerings are key to supporting this at scale (see the Scribe logging framework and the FBCrypto library). These properties often mean that solutions only have to be implemented once in order for the entire company to benefit.
This is especially true here. Most machines in Meta’s fleet can log to Scribe, giving us easy log ingestion support. Furthermore, the wide adoption of FBCrypto gives us insights into cryptographic operations without needing clients to migrate to a new library/API.
From an engineering perspective, this helps us overcome many hurdles that others in the industry might face. For example, it helps us avoid fragmentation that might require multiple custom solutions to be implemented, which would increase our engineering workload.
The impact of cryptographic monitoring
The insights from our cryptographic monitoring efforts have served multiple use cases across our security and infrastructure reliability efforts.
Preemptively mitigating security vulnerabilities
Thanks to our long retention window, we can monitor trends over time and use them for more predictive modeling and analysis. We can present our findings to cryptography experts, who can do further analysis and predict whether vulnerabilities may emerge. This allows us to preemptively identify clients using cryptography in risky ways and work with them to mitigate these issues before they become real security vulnerabilities.
This is particularly beneficial in preparation for the world of post-quantum cryptography (PQC), which requires us to find clients using vulnerable algorithms and ensure they are migrated off in a timely fashion.
We have also found that being able to preemptively detect these vulnerabilities well in advance has led to stronger support during cross-team collaborations. Thanks to the ample notice, teams can seamlessly integrate any necessary migration efforts into their roadmap with minimal interruption to their ongoing projects.
Promoting infrastructure reliability
Our root dataset has also served as a useful proxy for client health. This is partially thanks to the lack of sampling, as we can see the exact number of calls taking place, along with their respective success rates. This has been particularly important during large-scale migrations, where anomalous drops in success rate, call volume, etc., may indicate a bug in a new code path. Indeed, numerous detectors and alarms have been built off our dataset to help us perform big migrations safely.
The dataset also contains library versioning information, so we can monitor what versions of our library are running across the fleet in real-time. This has been especially useful for rolling out new features, as we can see exactly which clients have picked up the latest changes. This allows us to move faster and more confidently, even when running large-scale migrations across the fleet.
Challenges to cryptographic monitoring
Supporting cryptographic logging at Meta’s scale has had its own unique set of challenges.
Capacity constraints
Despite our optimizations, we have occasionally found ourselves putting increased load on Scribe (see point above about underestimating cryptographic usage) and have worked with the Scribe team to manage the unexpected increase in write throughput. Doing so has been relatively easy for the company, considering the design optimizations mentioned above.
We also occasionally put an increased load on Scuba, which is optimized to be performant for real-time data (i.e., warm storage) and can be inefficient if used for larger datasets. To minimize compute costs, we also rely on Hive tables for longer-term storage (i.e., cold storage).
Flushing on shutdown
Besides flushing the logs in the shared singleton map at a preconfigured time interval, client machines will also do one final flush to log all remaining contents of their log buffer to Scribe when a job is being shut down. We have found that operating in a “shutdown environment” can lead to a number of interesting scenarios, particularly when attempting to access Scribe and its dependencies. Many of these scenarios boil down to the nuances of folly::Singleton, which is Meta’s go-to library for managing singletons. Likewise, running something “on shutdown” in Java requires using only synchronous I/O code and operating quickly.
Our next initiatives for cryptographic monitoring
While our work thus far has been largely a success, there are many exciting avenues for improvements. For example, further optimizing Scribe throughput and Scuba storage utilization to make more efficient use of Meta’s infrastructure
We will also continue to leverage the logging data to further develop monitoring and data analytics to promote security and reliability. On the security side, this means continuing to take an inventory of use cases that would be vulnerable in a PQC world and migrate them to more resilient algorithms/configurations. In terms of reliability, it means gaining a better understanding of the end-to-end latency for cryptography use cases.
Within all of this it’s also important that we continue driving the unification of cryptographic offerings and monitoring tooling. While FBCrypto provides a unified set of offerings, there are other cryptographic use cases across Meta that use a different set of tools for telemetry and data collection. More non-trivial work is needed to achieve full unification with all use cases.
Acknowledgments
This work could not have been accomplished without the critical efforts of numerous folks, particularly Grace Wu, Ilya Maykov, Isaac Elbaz, and the rest of the CryptoEng team at Meta.