
Software isn’t what it used to be. That’s not necessarily a bad thing, but it does come with its own set of challenges. In the past, if you wanted to build a feature, you’d have to build it from scratch, without AI 😱 Fast forward from the dark ages of just a few years ago, and we have a plethora of third party APIs at our disposal that can help us build features faster and more efficiently than before.
The Prevalence of Third Party APIs
As software developers, we often go back and forth between “I can build all of this myself” and “I need to outsource everything” so we can deploy our app faster. Nowadays there really seems to be an API for just about everything:
- Auth
- Payments
- AI
- SMS
- Infrastructure
- Weather
- Translation
- The list goes on… (and on…)
If it’s something your app needs, there’s a good chance there’s an API for it. In fact, Rapid API, a popular API marketplace/hub, has over 50,000 APIs listed on their platform. 283 of those are for weather alone! There are even 4 different APIs for Disc Golf 😳 But I digress…
While we’ve done a great job of abstracting away the complexity of building apps and new features, we’ve also introduced a new set of problems: what happens when the API goes down?
Handling API Down Time
When you’re building an app that relies on third party dependencies, you’re essentially building a distributed system. You have your app, and you have the external resource you’re calling. If the API goes down, your app is likely to be affected. How much it’s affected depends on what the API does for you. So how do you handle this? There are a few strategies you can employ:
Retry Mechanism
One of the simplest ways to handle an API failure is to just retry the request. After all, this is the low-hanging fruit of error handling. If the API call failed, it might just be a busy server that dropped your request. If you retry it, it might go through. This is a good strategy for transient errors
OpenAI’s APIs, for example, are extremely popular and have a limited number of GPUs to service requests. So it’s highly likely that delaying and retrying a few seconds later will work (depending on the error they sent back, of course).
This can be done in a few different ways:
- Exponential backoff: Retry the request after a certain amount of time, and increase that time exponentially with each retry.
- Fixed backoff: Retry the request after a certain amount of time, and keep that time constant with each retry.
- Random backoff: Retry the request after a random amount of time, and keep that time random with each retry.
You can also try varying the number of retries you attempt. Each of these configurations will depend on the API you’re calling and if there are other strategies in place to handle the error.
Here is a very simple retry mechanism in JavaScript:
const delay = ms => {
return new Promise(fulfill => {
setTimeout(fulfill, ms);
});
};
const callWithRetry = async (fn, {validate, retries=3, delay: delayMs=2000, logger}={}) => {
let res = null;
let err = null;
for (let i = 0; i < retries; i++) {
try {
res = await fn();
break;
} catch (e) {
err = e;
if (!validate || validate(e)) {
if (logger) logger.error(`Error calling fn: ${e.message} (retry ${i + 1} of ${retries})`);
if (i < retries - 1) await delay(delayMs);
}
}
}
if (err) throw err;
return res;
};
If the API you’re accessing has a rate limit and your calls have exceeded that limit, then employing a retry strategy can be a good way to handle that. To tell if you’re being rate limited, you can check the response headers for one or more of the following:
X-RateLimit-Limit: The maximum number of requests you can make in a given time period.X-RateLimit-Remaining: The number of requests you have left in the current time period.X-RateLimit-Reset: The time at which the rate limit will reset.
But the retry strategy is not a silver bullet, of course. If the API is down for an extended period of time, you’ll just be hammering it with requests that will never go through, getting you nowhere. So what else can you do?
Circuit Breaker Pattern
The Circuit Breaker Pattern is a design pattern that can help you gracefully handle failures in distributed systems. It’s a pattern that’s been around for a while, and it’s still relevant today. The idea is that you have a “circuit breaker” that monitors the state of the API you’re calling. If the API is down, the circuit breaker will “trip” and stop sending requests to the API. This can help prevent your app from wasting time and resources on a service that’s not available.
When the circuit breaker trips, you can do a few things:
- Return a cached response
- Return a default response
- Return an error
Here’s a simple implementation of a circuit breaker in JavaScript:
class CircuitBreaker {
constructor({failureThreshold=3, successThreshold=2, timeout=5000}={}) {
this.failureThreshold = failureThreshold;
this.successThreshold = successThreshold;
this.timeout = timeout;
this.state = 'CLOSED';
this.failureCount = 0;
this.successCount = 0;
}
async call(fn) {
if (this.state === 'OPEN') {
return this.handleOpenState();
}
try {
const res = await fn();
this.successCount++;
if (this.successCount >= this.successThreshold) {
this.successCount = 0;
this.failureCount = 0;
this.state = 'CLOSED';
}
return res;
} catch (e) {
this.failureCount++;
if (this.failureCount >= this.failureThreshold) {
this.state = 'OPEN';
setTimeout(() => {
this.state = 'HALF_OPEN';
}, this.timeout);
}
throw e;
}
}
handleOpenState() {
throw new Error('Circuit is open');
}
}
In this case, the open state will return a generic error, but you could easily modify it to return a cached response or a default response.
Graceful Degradation
Regardless of whether or not you use the previous error handling strategies, the most important thing is to ensure that your app can still function when the API is down and communicate issues with the user. This is known as “graceful degradation.” This means that your app should still be able to provide some level of service to the user, even if the API is down, and even if that just means you return an error to the end caller.
Whether your service itself is an API, web app, mobile device, or something else, you should always have a fallback plan in place for when your third party dependencies are down. This could be as simple as returning a 503 status code, or as complex as returning a cached response, a default response, or a detailed error.
Both the UI and transport layer should communicate these issues to the user so they can take action as necessary. What’s more frustrating as an end user? An app that doesn’t work and doesn’t tell you why, or an app that doesn’t work but tells you why and what you can do about it?
Monitoring and Alerting
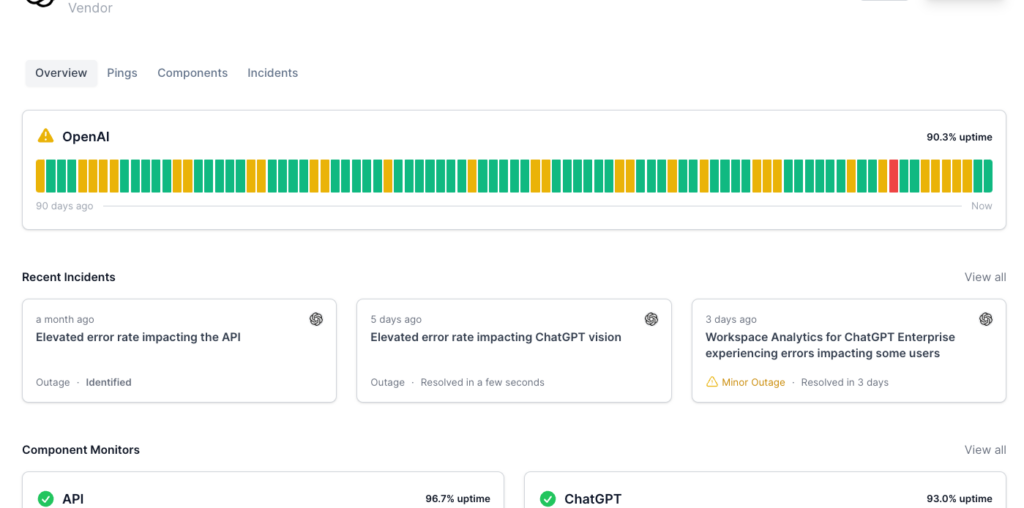
Finally, it’s important to monitor the health of the APIs you’re calling. If you’re using a third party API, you’re at the mercy of that API’s uptime. If it goes down, you need to know about it. You can use a service like Ping Bot to monitor the health of the API and alert you if it goes down.
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
Handling all of the error cases of a downed API can be difficult to do in testing and integration, so reviewing an API’s past incidents and monitoring current incidents can help you understand both how reliable the resource is and where your app may fall short in handling those errors.

With Ping Bot’s uptime monitoring, you can see the current status and also look back at the historical uptime and details of your dependency’s downtime, which can help you determine why your own app may have failed.
You can also set up alerts to notify you when the API goes down, so you can take action as soon as it happens. Have Ping Bot send alerts to your email, Slack, Discord, or webhook to automatically alert your team and servers when an API goes down.
Conclusion
Third party APIs are a great way to build features quickly and efficiently, but they come with their own set of challenges. When the API goes down, your app is likely to be affected. By employing a retry mechanism, circuit breaker pattern, and graceful degradation, you can ensure that your app can still function when the API is down. Monitoring and alerting can help you stay on top of the health of the APIs you’re calling, so you can take action as soon as they go down.