
Nov 26, 2019
This post was originally published on the Facebook AI blog.
Over half of the Instagram community visits Instagram Explore every month to discover new photos, videos, and Stories relevant to their interests. Recommending the most relevant content out of billions of options in real time at scale introduces multiple machine learning (ML) challenges that require novel engineering solutions.
We tackled these challenges by creating a series of custom query languages, lightweight modeling techniques, and tools enabling high-velocity experimentation. These systems support the scale of Explore while boosting developer efficiency. Collectively, these solutions represent an AI system based on a highly efficient 3-part ranking funnel that extracts 65 billion features and makes 90 million model predictions every second.
In this blog post, we’re sharing the first detailed overview of the key elements that make Explore work, and how we provide personalized content for people on Instagram.
Before we could execute on building a recommendation engine that tackles the sheer volume of photos and videos uploaded daily on Instagram, we developed foundational tools to address three important needs. We needed the ability to conduct rapid experimentation at scale, we needed to obtain a stronger signal on the breadth of people’s interests, and we needed a computationally efficient way to ensure that our recommendations were both high quality and fresh. These custom techniques were key to achieving our goals:
Iterating quickly with IGQL: A new domain-specific language
Building the optimal recommendation algorithms and techniques is an ongoing area of research in the ML community, and the process of choosing the right system can vary widely depending on the task. For instance, while one algorithm may effectively identify long-term interests, another may perform better at identifying recommendations based on recent content. Our engineering team iterates on different algorithms, and we needed a way for us to both try out new ideas efficiently and apply the promising ideas to large-scale systems easily without worrying too much about computational resource implications like CPU and memory usage. We needed a custom domain specific meta-language that provides the right level of abstraction and assembles all algorithms into one place.
To solve this, we created and shipped IGQL, a domain-specific language optimized for retrieving candidates in recommender systems. Its execution is optimized in C++, which helps minimize both latency and compute resources. It’s also extensible and easy to use when testing new research ideas. IGQL is both statically validated and high-level. Engineers can write recommendation algorithms in a Python-like way and execute fast and efficiently in C++.
user
.let(seed_id=user_id)
.liked(max_num_to_retrieve=30)
.account_nn(embedding_config=default)
.posted_media(max_media_per_account=10)
.filter(non_recommendable_model_threshold=0.2)
.rank(ranking_model=default)
.diversify_by(seed_id, method=round_robin)
In the code sample above, you can see how IGQL provides high readability even for engineers who haven’t worked extensively in the language. It helps assemble multiple recommendation stages and algorithms in a principled way. For example, we can optimize the ensemble of candidate generators by using a combiner rule in query to output a weighted blend of several subquery outputs. By tweaking their weights, we can find the combination that results in the best user experience.
IGQL makes it simple to perform tasks that are common in complex recommendation systems, such as building nested trees of combiner rules. IGQL lets engineers focus on ML and business logic behind recommendations as opposed to logistics, like fetching the right quantity of candidates for each query. It also provides a high degree of code reusability. For instance, applying a ranker is as simple as adding a one-line rule to our IGQL query. It’s trivial to add it in multiple places, like ranking accounts and ranking media posted by those accounts.
Account embeddings for personalized ranking inventory
People publicly share billions of high quality pieces of media on Instagram that are eligible inventory for Explore. It’s challenging to maintain a clear and ever-evolving catalog-style taxonomy for the large variety of interest communities on Explore — with topics varying from Arabic calligraphy to model trains to slime. As a result, content-based models have difficulty grasping such a variety of interest-based communities.
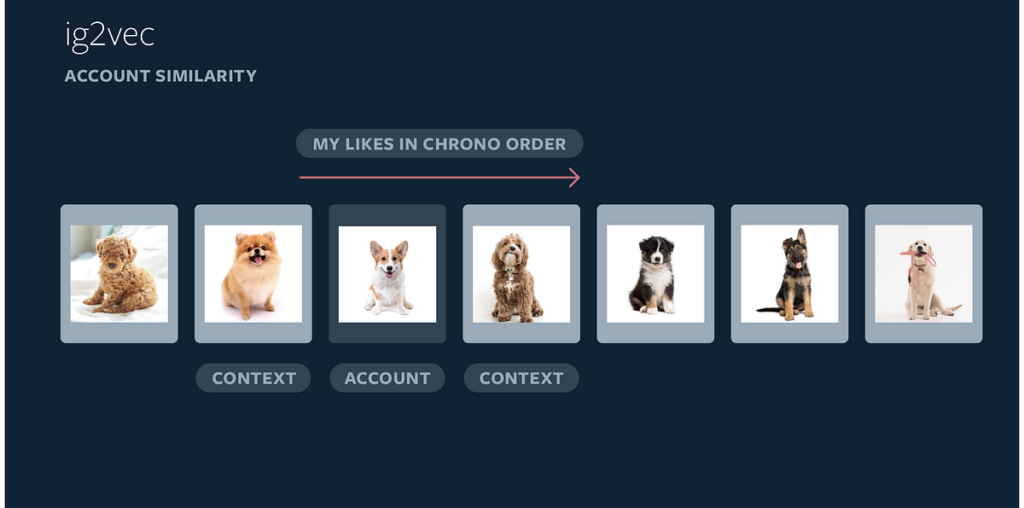
Because Instagram has a large number of interest-focused accounts based on specific themes — such as Devon rex cats or vintage tractors — we created a retrieval pipeline that focuses on account-level information rather than media-level. By building account embeddings, we’re able to more efficiently identify which accounts are topically similar to each other. We infer account embeddings using ig2vec, a word2vec-like embedding framework. Typically, the word2vec embedding framework learns a representation of a word based on its context across sentences in the training corpus. Ig2vec treats account IDs that a user interacts with — e.g., a person likes media from an account — as a sequence of words in a sentence.
By applying the same techniques from word2vec, we can predict accounts with which a person is likely to interact in a given session within the Instagram app. If an individual interacts with a sequence of accounts in the same session, it’s more likely to be topically coherent compared with a random sequence of accounts from the diverse range of Instagram accounts. This helps us identify topically similar accounts.
We define a distance metric between two accounts — the same one used in embedding training — which is usually cosine distance or dot product. Based on this, we do a KNN lookup to find topically similar accounts for any account in the embedding. Our embedding version covers millions of accounts, and we use Facebook’s state-of-the-art nearest neighbor retrieval engine, FAISS, as the supporting retrieval infrastructure.
For each version of the embedding, we train a classifier to predict a set of accounts’ topic solely based on the embedding. By comparing the predicted topics with human-labeled topics for accounts in a hold-out set, we can assess how well the embeddings capture topical similarity.
Retrieving accounts that are similar to those that a particular person previously expressed interest in helps us narrow down to a smaller, personalized ranking inventory for each person in a simple yet effective way. As a result, we are able to utilize state-of-the-art and computationally intensive ML models to serve every Instagram community member.
Preselecting relevant candidates by using model distillation
After we use ig2vec to identify the most relevant accounts based on individual interests, we need a way to rank these accounts in a way that’s fresh and interesting for everyone. This requires predicting the most relevant media for each person every time they scroll the Explore page.
For instance, evaluating even just 500 media pieces through a deep neural network for every scrolling action requires a large amount of resources. And yet the more posts we evaluate for each user, the higher the possibility we have of finding the best, most personalized media from their inventory.
In order to be able to maximize the number of media for each ranking request, we introduced a ranking distillation model that helps us preselect candidates before using more complex ranking models. Our approach is to train a super-lightweight model that learns from and tries to approximate our main ranking models as much as possible. We record the input candidates with features, as well as outputs, from our more complicated ranking models. The distillation model is then trained on this recorded data with a limited set of features and a simpler neural network model structure to replicate the results. Its objective function is to optimize for NDCG ranking (a measure of ranking quality) loss over main ranking model’s output. We use the top-ranked posts from the distillation model as the ranking candidates for the later-stage high-performance ranking models.
Setting up the distillation model’s mimicry behavior minimizes the need to tune multiple parameters and maintain multiple models in different ranking stages. Leveraging this technique, we can efficiently evaluate a bigger set of media to find the most relevant media on every ranking request while keeping the computational resources under control.
After creating the key building blocks necessary to experiment easily, identify people’s interests effectively, and produce efficient and relevant predictions, we had to combine these systems together in production. Utilizing IGQL, account embeddings, and our distillation technique, we split the Explore recommendation systems into two main stages: the candidate generation stage (also known as sourcing stage) and the ranking stage.
First, we leverage accounts that people have interacted with before (e.g., liked or saved media from an account) on Instagram to identify which other accounts people might be interested in. We call them the seed accounts. The seed accounts are usually only a fraction of the accounts on Instagram that are about similar or the same interests. Then, we use account embeddings techniques to identify accounts similar to the seed accounts. Finally, based on these accounts, we’re able to find the media that these accounts posted or engaged with.
There are many different ways people can engage with accounts and media on Instagram (e.g., follow, like, comment, save, and share). There are also different media types (e.g., photo, video, Stories, and Live), which means there are a variety of sources we can construct using a similar scheme. Leveraging IGQL, the process becomes very easy — different candidate sources are just represented as different IGQL subqueries.
With different types of sources, we are able to find tens of thousands of eligible candidates for the average person. We want to make sure the content we recommend is both safe and appropriate for a global community of many ages on Explore. Using a variety of signals, we filter out content we can identify as not being eligible to be recommended before we build out eligible inventory for each person. In addition to blocking likely policy-violating content and misinformation, we leverage ML systems that help detect and filter content like spam.
Then, for every ranking request, we identify thousands of eligible media for an average person, sample 500 candidates from the eligible inventory, and then send the candidates downstream to the ranking stage.
With 500 candidates available for ranking, we use a three-stage ranking infrastructure to help balance the trade-offs between ranking relevance and computation efficiency. The three ranking stages we have are as follows:
- First pass: the distillation model mimics the combination of the other two stages, with minimal features; picks the 150 highest-quality and most relevant candidates out of 500.
- Second pass: a lightweight neural network model with full set of dense features; picks the 50 highest-quality and most relevant candidates.
- Final pass: a deep neural network model with full set of dense and sparse features. Picks the 25 highest-quality and most relevant candidates (for the first page of Explore grid).

If the first-pass distillation model mimics the other two stages in ranking order, how do we decide the most relevant content in the next two stages? We predict individual actions that people take on each piece of media, whether they’re positive actions such as like and save, or negative actions such as “See Fewer Posts Like This” (SFPLT). We use a multi-task multi-label (MTML) neural network to predict these events. The shared multilayer perceptron (MLP) allows us to capture the common signals from different actions.
We combine predictions of different events using an arithmetic formula, called value model, to capture the prominence of different signals in terms of deciding whether the content is relevant. We use a weighted sum of predictions such as [w_like * P(Like) + w_save * P(Save) — w_negative_action * P(Negative Action)]. If, for instance, we think the importance of a person saving a post on Explore is higher than their liking a post, then the weight for the save action should be higher.
We also want Explore to be a place where people can discover a rich balance of both new interests alongside existing interests. We add a simple heuristic rule into value model to boost the diversity of content. We down-rank posts from the same author or same seed account by adding a penalty factor, so you don’t see multiple posts from the same person or the same seed account in Explore. This penalty increases as you go down the ranked batch and encounter more posts from the same author.
We rank the most relevant content based on the final value model score of each ranking candidate in a descendant way. Our offline replay tool — along with Bayesian optimization tools — helps us tune the value model efficiently and frequently as our systems evolve.
One of the most exciting parts of building Explore is the ongoing challenge of finding new and interesting ways to help our community discover the most interesting and relevant content on Instagram. We’re continuously evolving Instagram Explore, whether by adding media formats like Stories and entry points to new types of content, such as shopping posts and IGTV videos.
The scale of both the Instagram community and inventory requires enabling a culture of high-velocity experimentation and developer efficiency to reliably recommend the best of Instagram for each person’s individual interests. Our custom tools and systems have given us a strong foundation for the continuous learning and iteration that are essential to building and scaling Instagram Explore.
If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
Written by Ivan Medvedev, Haotian Wu, and Taylor Gordon.