

An Important Foundation For Security, Privacy, and Compliance at Airbnb

By: Sam Kim, Alex Klimov, Woody Zhou, Sylvia Tomiyama, Aniket Arondekar, Ansuman Acharya
Introduction
Airbnb is built on trust. One key way we maintain trust with our community is by ensuring that personal data is handled with care, in a manner that meets security, privacy, and compliance requirements. Understanding where and what personal data exists is foundational to this.
Over the past several years, we’ve built our own data classification system that adapts to the needs of our data ecosystem, to streamline our processes, and further unlock our ability to protect the data entrusted to Airbnb. This was made possible by many teams working closely to achieve this overarching, shared objective. Information Security, Privacy, Data Governance, Legal, and Engineering collaborated to tackle this problem holistically to produce a unified data identification and classification strategy across all data stores.
In this blog, we will shed light on the complexities of how data classification works at Airbnb, what measurements we set to assess the quality, performance, and accuracy of the systems involved, and the important considerations when building a data classification system. We hope to share insights for others that are facing similar challenges and to provide a framework for how data classification systems can be built at scale.
The Complexities of Data Classification at Airbnb
Data classification is the process of identifying where data exists and then organizing, detecting, and annotating that data based on a taxonomy. At Airbnb, we have established a Personal Data Taxonomy Council to define the taxonomy for personal data and to refine it over time. This taxonomy breaks down personal data into various data elements that are relevant for our ecosystem such as email address, physical address, and guest names. Once data is annotated with its applicable personal data element(s), various enforcement systems use these annotations to ensure personal data is handled according to our Security and Privacy policies. In this blog post, we will focus primarily on the data classification workflow and not each type of enforcement use case.
The workflow can be classified into three pillars:
- Catalog: What data do we have?
- Detection: What data do we suspect is personal data?
- Reconciliation: Which classification do we choose?
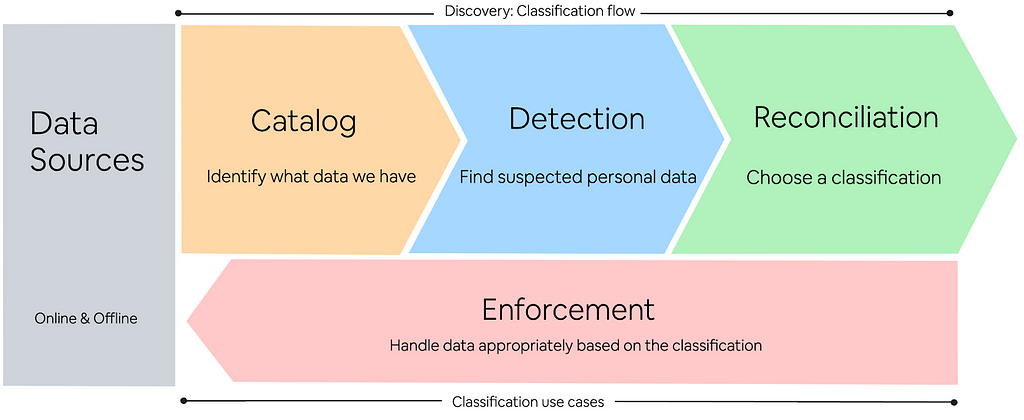
Let’s dig deeper into how each of these form the backbone of data classification.
Catalog
Cataloging involves building a dynamic, accurate, and scalable system to first identify where data exists and then organize the whole inventory. Cataloging is akin to mapping the data landscape or organizing a library. It involves dynamically discovering new data, enriching it with metadata from various sources, and manually inputting information. This process is crucial for enforcing data policies, accurately classifying data, and assigning it to the correct owners.
- Automated and Dynamic Discovery: Automation makes the cataloging process scalable and efficient. For the variety of data stores that Airbnb uses, such as production and analytical databases, object stores, and cloud storage, our catalogs connect to them and dynamically fetch the full inventory of data. Either through stream or batch processing, they dynamically update to reflect new and changed data. This ensures the catalog is a reliable and accurate source of truth.
- Complexity and Diversity in Data Sources: The challenge of cataloging stems from the variety and complexity of data sources, including different formats and locations. Our cataloging systems fetch metadata in several ways: through direct API calls or by crawling schemas in formats like thrift, JSON, yaml, or config files, accommodating the diverse nature of modern data storage.
For search and discovery, many of our data entities are surfaced in the data management platform, Metis. This helps the data owners quickly answer questions such as which data contains personal data, who owns the data, and which controls are in place.
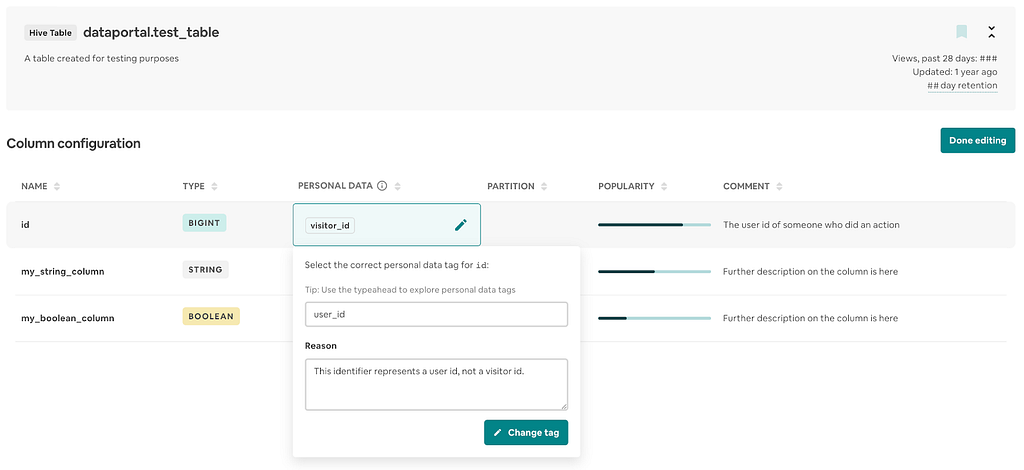
Detection
For personal data detection, we use the in-house automated detection service in our Data Protection Platform which was built to protect data in compliance with global regulations and security requirements. As our own taxonomy grows, we have expanded our capabilities and made the service easily extensible to detect all other types of personal data elements and personal Airbnb IDs.
Detection engine
For each data entity stored in the catalogs, scanning jobs are scheduled through a message queue, which then samples data and runs through our list of classifiers. Recognizing the need for periodic classifier updates, the detection engine was designed for simplicity and flexibility. Since its inception, our detection engine has upgraded to include additional steps and adopted the approach of configuration-driven development. The majority of the logic of the detection engine has been rewritten as simpler configurations to increase the speed of iterating on existing classifiers, improve testing, and enable quick development of new features.
The detection engine can be seen as a pipeline, which involves the scanner, validator, and thresholding.
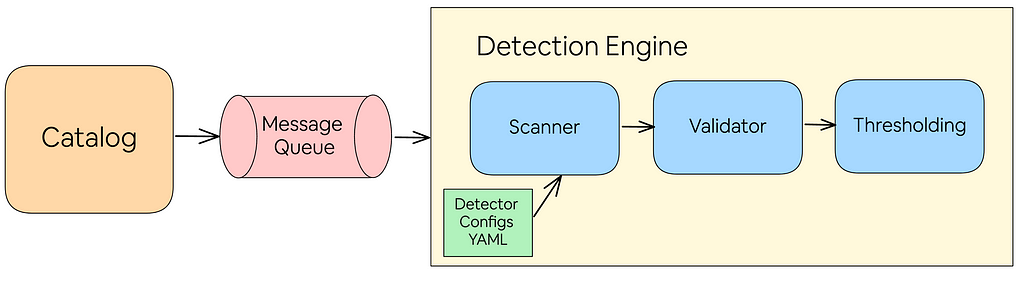
Scanner: The scanner classifies personal data using metadata and content, employing methods like regex for emails and keyword lists for cities, and advanced machine learning models for complex data types requiring contextual understanding.
Validator: Sampled data matching a scanner undergoes a customizable validation step to enhance classifier accuracy, verifying details like latitude/longitude ranges or custom ciphertexts from encryption services.
Thresholding: To reduce noise, thresholding is applied before storing results, varying by data structure type (e.g., matched rows vs. findings in a document) and set based on historical data frequency and criticality.
With the revamped pipeline, this has resulted in a significant decrease in false positive findings and reduced the burden on data owners to verify every result, which has historically impeded their productivity.
Reconciliation
Not every detection surfaced may be correct or, in other cases, more context may be required. Therefore, we employ a human-in-the-loop strategy: where data owners confirm the classifications. This step is critical in ensuring these classifications are correct before any data policies are automatically enforced to protect our data.
Automated Notifications
For compliance, we have an automated notification system that issues tickets whenever personal data is detected. These get surfaced to the appropriate data or service owners with strict SLAs.
For data entities that have schemas defined in code, such as transactional tables from production services (online), Amazon S3 buckets, or tables that are exported to our data warehouse, we assist the developers by automatically creating code changes that update their table schemas with the detected personal data elements.
Enforcing resolution
To enforce resolution on these tickets, tables are automatically access controlled in the data warehouse when the tickets are not resolved within SLA. Additionally reviews are conducted to ensure our classifications are correct for data where its handling requirements apply.
Tracking actions taken on these tickets for when personal data is detected has been important to assess the quality of our data classification flow and to keep an audit trail of past detections. It also highlights points of friction developers face when resolving these tickets. The investments we have made in this area have continued to improve the process and reduce the time needed to resolve tickets each year.
Assessing Quality of a Data Classification System
Because of the complexity of the system and its sub-components, this presented a unique challenge as we strive to define what quality means for the entire system. To build with the long-term in mind, we evaluated how well our entire data classification system functions as a whole.
We’ve set up measurements to assess quality of our data classification in three categories:
Recall: This measures our coverage and ability to not miss where personal data may exist, crucial for protecting the stored personal data. We assess recall through:
- Number of data entities integrated in the data classification system
- Volume of personal data that exists from all different sources
- Types of personal data being annotated and automatically detected against our taxonomy
Precision: This evaluates the accuracy of our data classifications, vital for data owners tagging their data. High precision minimizes tagging friction. Precision is measured by:
- Tracking false positive rates of classifiers for each type of personal data
- Tracking ticket resolutions made by data owners, which also aids in understanding nuanced classification cases
Speed: This gauges the efficiency of identifying and classifying personal data, aiming to minimize compliance risks. Speed is measured by:
- Time it takes for the detection engine for scanning new data entities
- Time it takes for data owners to reconcile classifications and resolve tickets
- The frequency of data tagging at creation by data owners
These measurements ensure our data classification system is effective, accurate, and efficient, safeguarding our personal data.
Considerations for Building a Data Classification System
It is important to be aware of issues that may be present with the outlined approach in general. Below are some challenges that we’ve considered when building a data classification system:
- Post-Processing Classification: The outlined approach mostly relies on post-processing classification, which means that schema information is added after data has been collected and stored. In a modern data world where data and metadata are constantly changing, post-processing cannot catch up with data evolution.
- Inconsistent Classifications: Data generally flows from online to offline through ETL (extract, transform, and load) processes, and then reverse ETLing back to the online world. However, data classification that is performed independently in both worlds can lead to inconsistent classifications.
- Waste of Process Cost: Duplicate annotations can be made for the same data in the online and offline domains, which might result in increased costs for data classification processes.
To address these challenges, we describe the process of “shifting left” with data classification and how we started to push developers to annotate their data at the beginning of the data lifecycle.
Shifting Left
Instead of thinking about governance and data classification as an activity that happens post-hoc, we’ve started to embed the annotation process directly into data schemas as they are being created and updated. This enables us to:
- Shift Classification from Data to Schema: The schema annotation process takes place earlier in the data lifecycle at the point of data collection. This keeps annotations updated as data evolves and ensures data is annotated before collection and consumption, allowing for immediate policy enforcement.
- Shift Classification from Offline to Online: Traditionally done offline, data classification is now integrated into production services, ensuring data is structured and formatted correctly from the start. Leveraging data lineage information enables automated annotation, reducing the need for manual effort and lowering process costs.
- Shift from Data Steward to Data Owner: Oftentimes, stewardship, or the responsible management and oversight, of the data is conducted by people who are downstream of data creation, such as data consumers or governance professionals. This change shifts stewardship to the data producers, merging the roles of data steward and data owner. This empowers the team that owns the data to manage it more effectively and scale operations.
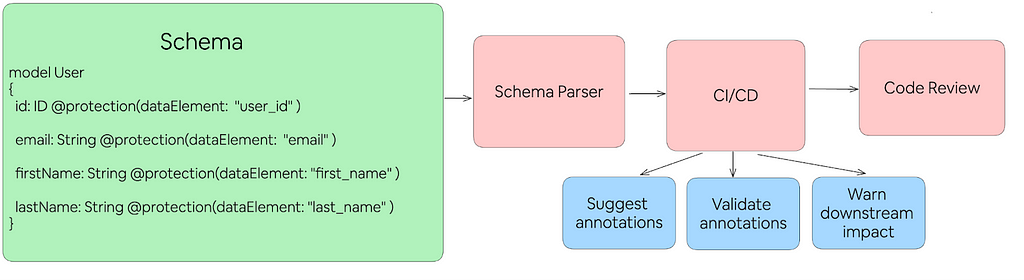
Schema Annotation Enforcement
Focusing on our most crucial online data, we have started executing on shifting left by directly integrating with our internal schema definition language that is known for its annotation capabilities. We now mandate that developers include personal data annotations at the source when creating new data models, providing guidance on accurate tagging. This requirement is enforced through checks that run in our CI/CD pipelines which:
- Automatically suggest data elements: Based on the schema’s metadata, we automatically detect the data elements for all fields defined in the schema with our detection service.
- Validate data elements: Annotations are validated against our own taxonomy and schemas are enforced and all fields are annotated, even when it is not considered personal.
- Warn about downstream impact: We notify data owners when annotations can impact downstream services such as offline data pipelines and direct them to the proper resources for handling.
While shifting left has significantly helped to push classifying data earlier and increase coverage of schema annotations, this does not discount the importance of the rest of the classification process. Classifications that happen post-process are necessary for instance in cases where data storages that do not include well-defined schemas. Therefore, continued investments are still needed in detection and reconciliation to cover areas that cannot be shifted left and to verify annotations that may have already been made by owners as a second layer of protection.
Conclusion/Lessons Learned
The Airbnb data classification framework has been successful in advancing data management, security, and privacy. Reflecting on the journey, it has offered invaluable insights that have shaped our methodologies. Key takeaways include:
- Adopting a unified strategy for classifying online and offline personal data to streamline processes
- Implementing a ‘Shift Left’ approach to engage with data owners early in the development cycle
- Addressing classification uncertainties through clear guidelines and decision-making
- Enhancing education and training initiatives for data owners and consumers
As the data landscape continues to rapidly change, these lessons will guide future data classification efforts and ensure continued trust and protection of customer data.
Acknowledgements
Our data classification strategy has evolved over many years and we’ve been able to quickly adapt and iterate thanks to our decision to build an in-house solution. Security, privacy, and compliance are of utmost importance at Airbnb, and this work would not be possible without the contribution of many of our cross-functional partners and leaders.
This includes, but are not limited to: Bill Meng, Aravind Selvan, Juan Tamayo, Xiao Chen, Pinyao Guo, Wendy Jin, Liam McInerney, Pat Moynahan, Gabriel Gejman, Marc Blanchou, Brendon Lynch, and many others.
If this type of work interests you, check out some of our related positions at Careers at Airbnb or check out more resources in the Airbnb Tech Blog!
All product names, logos, and brands are property of their respective owners. All company, product and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.
Personal Data Classification was originally published in The Airbnb Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.