
Models in Kotlin with data classes are already leaner and cleaner than their Java counterparts. Abstracting away all those getters, setters, toString() and copy() method with a single keyword makes our models reflect the only thing they should be concerned about — holding data.
As I was exploring Swift for a project, I came across a lovely concept of separating business or transformation logic from models with the help of extensions. This week, we will apply this concept to our Kotlin data classes.
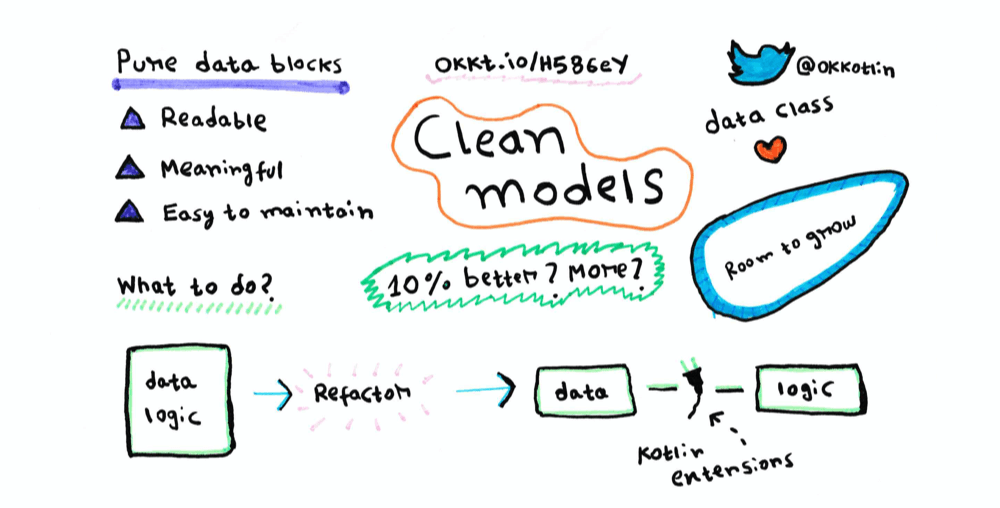
When requirements outgrow a pure data class
A simple data class in our project is the purest form of a model we can have. I mean, look at this:
data class Podcast(
val name: String,
val description: String,
val category: String,
val publisher: String,
val website: String
)One quick peek and we know it’s a Podcast model and what data we need to provide to get an instance of this class.
The data keyword indicates that we have access to all those fancy methods like, copy() and toString() without any extra line of code.
In reality, however, our model classes might have to do a bit of extra work than just being data containers. Having convenience methods to format data from model class properties is a known practice.
From a bird’s eye view, the following class will probably seem fine:
data class Podcast(
val name: String,
val description: String,
val category: String,
val publisher: String,
val website: String
) {
fun getPublisherMeta(): String = "$publisher: $website"
fun getQualifiedUrl(): String = "https://$website"
}After all, there’s nothing wrong in having two convenience methods to print out podcast meta data. They are strongly related to the model we are working with.
However, adding utility methods inside our models tank their readability level. Our model is no longer a simple container for data. It has logic mixed up with data.
Throw in a few more methods, and we will no longer have that “one quick peek to know the data” readability.
Should we put logic inside our model classes?
Having logic inside a model class is fine. But imagine:
What if we could have some boundary between the data and logic in our models?

That would make our models stay true to their name. One separate block of code depicting a pure data entity and nothing more.
data class Podcast(
val name: String,
val description: String,
val category: String,
val publisher: String,
val website: String
)Now, the question that comes is where exactly to put any added functionality if not within the class itself. There’s a Kotlin way to this problem.
Added functionalities as extensions
We can use Kotlin’s extension functions to cut-paste logic from our data classes to top-level functions.
With this approach, our previously bloated data class breaks down into two separate units:
data class Podcast(
val name: String,
val description: String,
val category: String,
val publisher: String,
val website: String
)
fun Podcast.getPublisherMeta(): String = "$publisher: $website"
fun Podcast.getQualifiedUrl(): String = "https://$website"Even if we add a hundred extension functions, from a readability standpoint, our Podcast model is still lean and a separate block of code. Also, functionality wise, this approach is essentially the same as that we had before.
That means, we can still call getPublisherMeta() on a Podcast instance, and it will return the correct value depending on which instance we are calling the method on.
The only difference is, our model classes read better now.
We can go a step further here and extract out the extension functions in a separate file. However, that kind of separation is often unnecessary.
Your mileage may vary
There’s no one way to achieve something. Programming is a significant proof of this concept. Programmers have their particular coding style preferences.
I would suggest you take this approach out for a spin and see if it makes sense for your projects. It’s a small refactor with a decent treat for your and your teammates’ eyes.
Here’s a sketch note on the topic
