
The Instagram community is bigger and more diverse than ever before. 800m people now visit every month, 80% of whom are outside of the United States. As the community grows, it becomes more and more important that our app can withstand diverse network conditions, a growing variety of devices, and non-traditional usage patterns. The client performance team at Instagram New York is focused on making Instagram fast and performant, no matter where someone is using it.
Specifically, our team prioritizes instantaneous content delivery, zero wasted bytes over the network, and zero wasted bytes on disk. We recently decided to focus on effective background prefetching as a way to break the dependency of Instagram usability from network availability and a user’s data plan.
Network availability

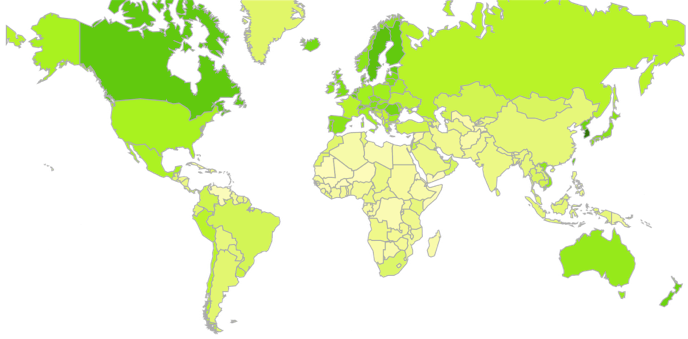
Most of the world does not have enough network connectivity. Michael Midling, our data scientist, put together this map to represent the average network bandwidth while using Instagram in different countries around the world. Darker green regions, like Canada, have somewhere around 4+Mbps, vs. lighter green areas like India, which have an average network bandwidth of 1Mbps.
We cannot assume that media will be available to watch when a user opens Instagram and starts watching stories or scrolling through feed. If you want to build a fast media app in India, where network availability is not rich and a round-trip time could be above two seconds, you need to come up with a different strategy than fetching resources in realtime. If we want everyone to be able to access Instagram and see videos and photos from their closest friends and interests, we have to be able to react to different network bandwidth speeds. Building apps that adapt to these network conditions has its challenges.
Data sensitivity
One of our solutions was to add the user’s connection type into our logging events. This allowed us to observe the different usage patterns divided by connection type, which helped us adapt. We strive to be respectful of people’s data plans and try to maximize the data sourced over unmetered connections.

The graph shows how Instagrammers around the world access our app. For example, we need to adapt to the network patterns in Indonesia where people are switching from one SIM card to another as soon as they run out of data and mainly access the app on cellular connection. On the other hand, people in Brazil mostly use our app over wifi.
Network failure

What if the network fails all together? Historically we would display a screen with grey boxes and hope for the user to come back and retry when they had a better connection. But this isn’t a good experience.

Sporadic network connection and cellular network congestion are also concerns. When we’re in one of the light green areas of the map above, where network bandwidth is low, we need to find a way to shorten or eliminate people’s wait time.
Our goal is for people to perceive no network connection as being online, but there is no one-size-fits-all solution for this. Below are some of the techniques we apply to adapt the offline experience to different types of usage in different conditions.
We came up with a series of strategies. First, we focused on building the Offline Mode experience. With this experience we unlocked the possibility to deliver the content from disk as if it is coming from network. Second, leveraging this cache infrastructure, we built a centralized background prefetching framework, to populate this cache with unseen content.
Offline principles
Through data analysis and user research, we’ve come up with a few principles that represent the major pain points and areas for improvement:
- Offline is a status, not an error
- The offline experience is seamless
- Build trust through clear communication
You can see how this was implemented in the video:
Decoupling network availability and app usability
Using the response store, image and video cache, we can deliver content to the UI screen when it’s not retrieved from the network, which simulates a successful network call.
There are three main components: the device screen, the device network layer that composes the HttpRequests, and the device network engine that takes care of delivering our network requests to the server.
After building the ability to deliver content from disk, we noticed improvements to how people used Instagram in high-growth markets. We decided to cache the content after downloading from the network with the belief that seeing older content would be better than seeing gray boxes and white screens. But the ideal solution was still showing new content. That’s where background prefetching came in.
At Instagram one of our engineering values is “do the simple thing first,” so our first approach was not to build the perfect background prefetching framework. The first prototype just prefetched data when the app got backgrounded, if and only if the user was under wifi connection. This BackgroundPrefetcher iterated through a list of runnables, executing one by one.
This first prototype allowed us to:
- Iterate on kinds of content to prefetch
- Analyze the actual effects of delivering unseen cached content on the user experience
- Benchmark final framework (stability)
public void registerJob(Runnable job) {
mBackgroundJobs.add(job);
}@Override
public void onAppBackgrounded() {
if (NetworkUtil.isConnectedWifi(AppContext.getContext())) {
while (!mBackgroundJobs.isEmpty()){
mSerialExecutor.execute(mBackgroundJobs.poll());
}
}
}
The reality is that apps are complex, and so are people! When it comes to deciding what type of media to prefetch, you have to carefully analyze usage patterns. For example, some people may use some features more than others.
Our home screen has a great diversity of items, from the Stories tray to individual stories media. We could also prefetch photos and videos for feed, the messages that you have pending, items for you to browse in Explore, or your most recent notifications. In our case we started simple, only prefetching some media for Explore, Stories and main feed.
Building a centralized framework that is flexible enough to adapt to different use cases helps us maintain efficiency and scale properly.
Apart from the ability to schedule the jobs in our framework that prefetched data with no control on the background, we added extra logic on top. Centralizing the logic for background prefetching to a single point made it possible to apply rules and verify that certain conditions are met, like:
- Control connection type -> unmetered
- JobCancellation -> if conditions change or app gets foregrounded, we want to be able to cancel whatever work we were doing
- Batching requests together, and prefetching only once, at the most optimal time, in between sessions
- Collect Metrics → how long does it take for all the work to be finished? How successful are we at scheduling and running the background prefetching jobs?
Workflow

Let’s take a look at the workflow for our background prefetching strategy on Android:
- When the main activity starts (meaning that the app gets foregrounded), we instantiate our BackgroundWifiPrefetcherScheduler. We also enable what type of jobs will be run.
- This instance registers itself as a BackgroundDetectorListener. For context, we have implemented a structure that will tell us every time that the app gets backgrounded in case we want to do something before the app gets killed (like sending analytics to the server).
- When the BackgroundWifiPrefetcherScheduler gets notified, it calls our home-made AndroidJobScheduler to schedule the background prefetching work. It will pass in the JobInfo. This JobInfo contains information about what service to launch, and what conditions need to be met in order for this work to get kicked off.
Our main conditions are latency and unmetered connections. Depending on the Android OS, we may take other things into consideration, like if power saving mode is enabled or not. We have experimented with different values of latency, and we are still working to provide a personalized experience. Currently we prefetch on background only once in between sessions. To decide at what time we will do this after you background the app, we compute your average time in between sessions (how often do you access Instagram?) and remove outliers using the standard deviation (to not to take into account those times where you might not access the app because you went to sleep if you are a frequent user). We aim to prefetch right before your average time.
- After that time has passed by, we check if the connection conditions met our requirement (unmetered/wifi). If this is the case, we will launch the BackgroundPrefetcherJobService. If not, this will be pending until the connection condition is met. (Or device is not in battery saving mode if applicable).
- BackgroundService will create a serialExecutor to run every background job in a serial fashion. However, after obtaining the http response, we prefetch media in an asynchronous manner.
- After all the work is done, we notify the OS so our process can be killed and we optimize for memory/battery life. Killing this running service on Android is important to release memory resources that will not be used anymore.
All of this is user scoped. We need to be able to address when someone logs out or the user switches. If the user logs out, we will cancel the scheduled work to avoid waking up the service unnecessarily.
IgJobScheduler
For Android specifically, we:
- Looked for an effective way to schedule jobs on background so we could persist data across sessions and specify network requirements.
- Analyzed how many users were under Lollipop (Android OS released on 2014) as the APIs for Android JobScheduler interface were only available starting on this OS. Turned out this was a case we could not skip…. we needed a compatible version for people using Lollipop.
- Researched to find an open source/existing solution to schedule jobs on Android for older OS versions. Despite of finding great libraries, none of them fit our use case, as they pulled a dependency on Google Play Service. For context, on Instagram we believe on maintaining our first in class position in terms of APK size.
- Finally, we ended up building a custom-performant compatible solution for Android JobScheduler APIs.
Measurement
At Instagram we are very data driven and rigorously measure the impact of the systems that we build. That is why when we were designing our background prefetching framework we were also thinking about what metrics should be in place to get the proper feedback.
The fact that we count with a centralized framework also helps us collect metrics at a higher level. We thought that it was very important to accurately evaluate the trade-offs and be able to answer questions about how many prefetched bytes were unused or what global CPU regressions were caused.

One thing that helped us a lot is that we mark/associate a network request policy to every network request to indicate its behavior and type. This was already built into the app but we leveraged it to slice our prefetching metrics. We attach a request policy to the http request fired and specify if the request is a prefetch request. Another thing that we specify in the policy is the requestType. A request can be specific for Image, Video, API, analytics, etc. This will help us with:
- Request prioritization
- Better analyze trade offs by dimensiom like global CPU regression, data usage, and cache efficiency
/**
* The policy behavior describes whether the associated request is
needed to render something
* on the screen, or not (e.g. prefetch).
*/
public enum Behavior {
Undefined(-1),
OffScreen(0),
OnScreen(1),
; int weight; Behavior(int weight) {
this.weight = weight;
}
}
Here we can see a snapshot of that requestPolicy object as defined in our Android codebase. We define a request to be “on screen” when the request belongs to a content that the user is waiting for. offScreen requests have a probability > 1% of the user not interacting with this data requested.
Cache efficiency logger
We wanted to know how many of our prefetched bytes were actually used, so we looked into how items placed in the cache were being used. We built our entire cache logger in a way that met the following specs:
- Be scalable. It should be able to support new added caches instances through its API.
- Be fault tolerant and robust. It should tolerate cache failures (no logging action) or inconsistencies across timestamps.
- Be reliable. It should persist data across sessions.
- Use minimal disk and latency on logging. Cache reads/writes happen very often, therefore we want to add minimal overhead. The logging during cache reads/writes can lead to more crashes and higher latency.

We also wanted to know how much data we used when we added a new background prefetch request. We have a layered base network engine on the device, and as we mentioned, we attach a requestPolicy to every network request. This makes it super easy for us to track data usage in our app, and observe how much data we consume downloading images, videos, JSON responses, etc.
We also wanted to analyze how the data usage gets distributed between data usage over wifi vs. data usage over cellular. This unlocked the possibility of experimenting with different prefetching patterns.
Other benefits
What other benefits can background prefetching give you beyond breaking the dependency on network availability and reducing cellular data usage? If we reduce the sheer number of requests made, we reduce overall network traffic. And by being able to bundle future requests together, we can save overhead and battery life.
Preventing regression
Something that we took into account before implementing background prefetching is the potential risk of causing global CPU regression.
And how can you cause regression? Let me give you an example. Imagine our endpoint that serves the API to get your Instagram main feed. Person A’s device will make a call to the main feed API every time person A opens Instagram to get the latest feed first page. This API has several heavy computational operations like ranking and categorizing content based on seen state. If we then do background prefetching every time in between sessions, we would be increasing the load considerably, right?
In an attempt to minimize the server side regression, for our first version of the background prefetcher system, an engineer on the feed team, Fei Huang, opened up a different endpoint for background prefetching. This one just fetches new feed posts that are not in view state and return the newest N=20 items.
This was our workflow process when building our system. Our team did not open the API to other engineers until we could ensure the quality of the framework and the benefit to the user.
As more people join Instagram, this work only becomes more important. We look forward to keep making Instagram more efficient and performant for everyone around the world.
Lola Priego is a software engineer on the client performance team at Instagram New York.