

Summary:
Generative AI systems are prediction machines. This article breaks down neural networks and LLMs in nontechnical language.
Want to understand how large language models (LLMs) work without getting too deep into the math? Read on for a greatly simplified explanation of a monstrously complex technical topic. I’m using metaphors to prioritize understanding rather than technical accuracy. For an even more in-depth explanation that’s still intended for nontechnical audiences, I recommend this article by Timothy B. Lee and Sean Trott.
High-Level Overview
Don’t want to read the whole article? Here’s a quick overview.
Large language models are probabilistic systems that attempt to predict word sequences. That’s what generative AI systems (genAI) do — they are making word-by-word predictions in the context of your prompt. LLMs are not fact databases; they statistically model how words tend to appear together based on their training data.
LLMs are based on a neural network architecture. Neural networks are computational systems made up of layers of neurons; a neuron performs a simple math function on its inputs. Each neuron’s output is weighted, meaning that it is multiplied by a number that captures how important it is compared to other neurons’ outputs. Neural networks are trained on large amounts of data in order to “learn” the weights that produce the best outputs.
In LLMs, words (or word fragments) are encoded as word embeddings — a series of coordinates in a multidimensional abstract space, where words with similar meaning or purpose are near each other. This representation allows the AI to “reason” with words by looking at the relative distance between them and, thus, assemble them in a meaningful way based on the context. Word embeddings are also learned by LLMs during the training phase.
Once an LLM system is trained, it is refined by feeding it conversational data (where humans have written both the “human” and “AI” parts) and other refinement training data. Humans then evaluate the outputs of various test scenarios, rewarding the system when it “aligns” with human expectations.
Probabilistic Sequence Prediction, Not Magic
Generative-AI (genAI) tools are fundamentally sequence-prediction machines. What does this mean? By and large, these systems complete a sequence with whatever is most likely to appear.
A Simple Example of Sequence Prediction
Consider the idiom “It’s raining cats and ____.” If you present this incomplete sentence to a genAI system, the response will likely be the word “dogs.” This is because that pattern (“raining cats and dogs”) often occurs in written English. When you input a prompt into a system like ChatGPT, Gemini, or Claude, it tries to predict the next words that would follow your sentences.
Think of it like a complicated version of the word game Mad Libs — there’s a blank space in a sentence, and the system wants to fill it with a word. Instead of trying to come up with a ridiculous word for a humorous effect, genAI systems aim to provide the most likely response.
The fact that these AIs can perform so well is amazing. Human language is predictable enough for a system to fill in the blanks convincingly, but only after reading nearly the entire internet first.

Even more interestingly, the system’s output isn’t just a guess of the next word — it’s multiple top guesses of the next word, along with their relative probabilities. Engineers can then adjust how “loose” or “creative” the system is allowed to be in selecting from the short list of candidate words (by controlling options such as temperature).

An LLM can predict the next word because it is, essentially, a statistical model of language built with neural networks.
From Fill-in-the-Blank to Complex Answers
If generative AI systems are just playing a complicated game of Mad Libs, then how do they generate complex answers or perform complete tasks? Predicting the next word in a sequence that already exists is quite different from generating a relevant answer to a question.
LLMs are not just trying to predict a single next word (though that’s the core of the process); they are trying to complete a whole conversation, and that conversation includes your prompt as part of it. The response is the “blank” the AI is supposed to fill.
The AI does not necessarily make this prediction of the response sequentially, one word at a time. A recent breakthrough is the transformer (see below), which is a type of computational architecture that allows each word to be “aware” of all the other words in the passage.
Think of it like social groups in high school. They are self-organizing: no one person assigns people to social groups. Each person finds a group where they “fit in,” and is also aware of their role in the larger community; they know many of the other people around them (even if they aren’t directly friends) and what group they belong to. Also, each person adjusts their behavior a bit to fit in better in their groups and the community.
What’s a Neural Network?
LLMs are built from neural networks. If we imagine that an LLM is a conductor, the neural network is the orchestra, and the individual neurons are the individual musicians. Each musician may be playing something rather simple on their own but put a bunch of them together in combinations that make sense, and you have something that can be used to voice melodies and harmonies.
Neural networks are computer systems inspired by how brains are organized, but in practice, they’re very different from biological brains. They build statistical models to predict a specific output given an input. They self-modify their statistical model based on their training data -– they “learn” to better predict the correct output after seeing many inputs.
A neural network consists of neurons (also called nodes) — a series of simple math functions that are arranged in interdependent layers:
- An input layer takes in input data
- An output layer outputs the prediction
- One or more hidden layers in between progressively influence each other
(The neural networks used in genAI are called “deep” because they have several layers.)

Typically, the outputs of all the neurons in each layer are connected to the inputs of all the neurons in the next layer. So, each neuron takes as input the sum of all the outputs of the neurons in the previous layer. Since each neuron has a different level of importance, the output of that neuron has a weight applied to its output.
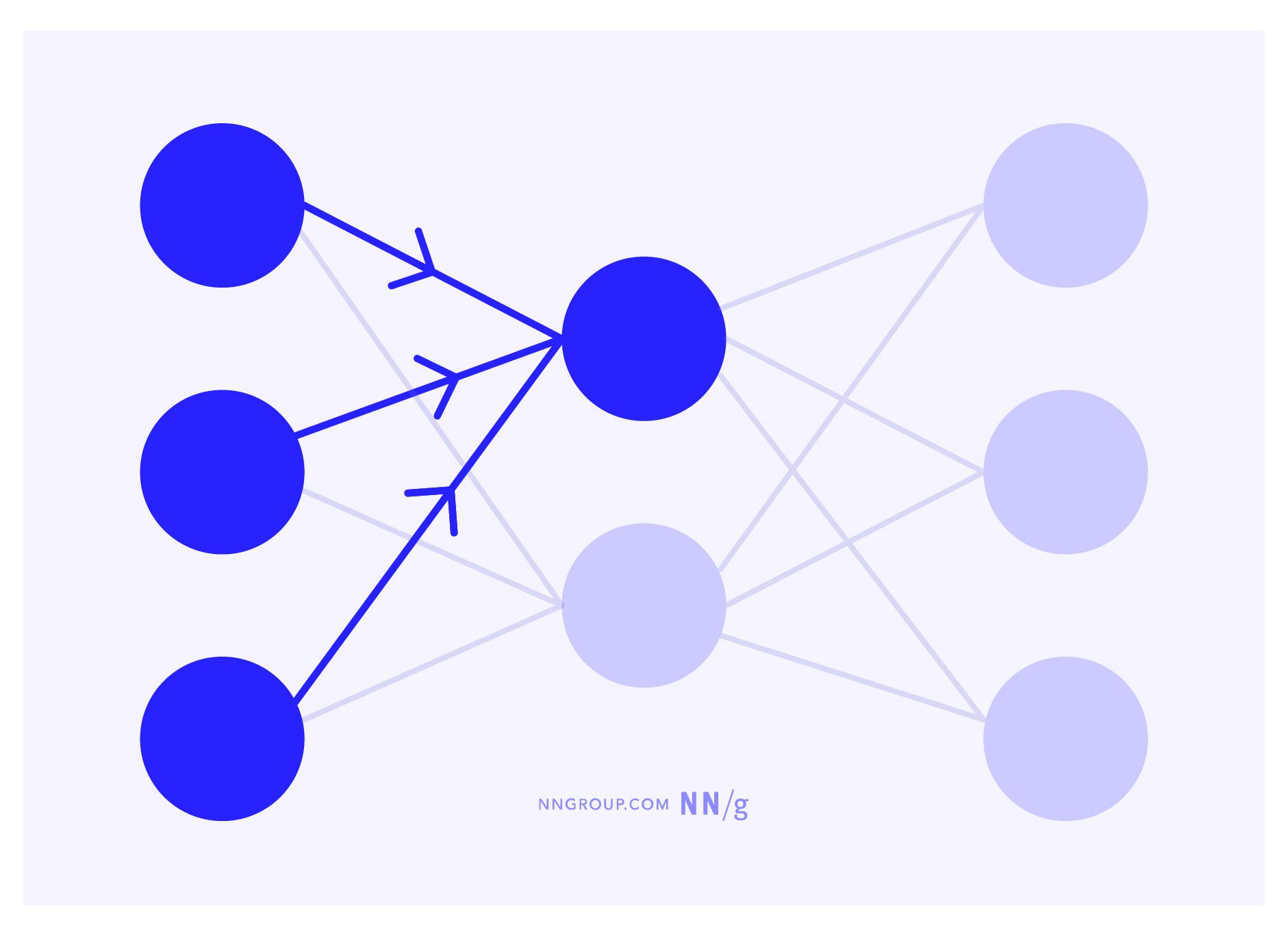
How Individual Neurons Work
Each neuron takes one or more numeric inputs and performs a mathematical function to evaluate the input. Each neuron has its own number (called the bias) to which it adds the sum of all its inputs. This bias shifts the total sum, and then passes it to an activation function. The activation function then mathematically “decides” whether the neuron passes along its output number to the next layer or not.

Those weights and the biases of each neuron are an important part of the neural network, and they are sometimes called the parameters of an AI system. When an AI system is described as having billions of parameters, that’s referring to those weights and biases.
Modern generative AI systems have many layers. The older GPT-3 has 96 layers, with 175 billion parameters (aka weights and biases of all the network’s neurons). They are set in training —a process through which the network learns the right weights by being exposed to large volumes of training data. (For GPT-3, that learning data is written text.).
How Are Words Represented in LLMs?
All the previous discussion of neural networks describes math functions, but words aren’t numbers. How do neural networks deal with words?
LLMs work with word embeddings — detailed vector representations of words that take into account each word’s meanings and relationships with other words. These representations allow them to do calculations on how similar two words are.
From your elementary school geometry classes, you probably remember that a point in two-dimensional space can be represented by two numbers (x,y) that reference the two axes. That is an example of a 2-dimensional vector. We can then do all sorts of fun math to compare how far apart any two points are in that two-dimensional space.

Language is much more complex than that, so modern LLMs don’t use two-dimensional space, they use hundreds (or thousands) of dimensions. A word is a point (i.e., vector) in this multidimensional space, and the distance between two words can be mathematically calculated by a formula like that used in elementary geometry. Two words that have similar meanings will tend to be close to each other in this space (and vice versa).
(Note that LLMs actually embed tokens, which can be either full words or word fragments, but for the purposes of this section, I’ll refer to words rather than tokens.)
So, let’s say we wanted to represent the word water. The LLM will take that word and turn it into a vector of coordinates in a multi-dimensional space so that it can reason how far away one word is from another. Thus, water will be placed somewhere near ocean, since they often appear in similar contexts. Sand would be close to desert.

So, each word is represented as a long list of dimensions. What do each of those dimensions represent? Well, it is not precisely known what each of these dimensions is encoding.
This is partly why AI is often called a “black box.”
Some of the dimensions seem to have to do with grammatical or syntactical purposes (like verbs, nouns, etc.), some seem to describe semantic features (what the word means), and others might capture features such as tone. But the dimensions are abstract representations of how the words relate to each other, rather than a humanly understandable taxonomy of every concept in the world. A lot of the state-of-the-art research in AI is attempting to create mechanistic interpretability (i.e., a concrete understanding of what happens inside the AI).
Part of the training of an LLM consists of creating these detailed word embeddings that allow the AI to represent and work with language. Training involves processing large amounts of text and learning from it functional representations of words. The larger the training corpus, the better and more nuanced the embeddings will be.
What Is a Transformer?
Large language models generally use a special type of neural network called a transformer (the T in “GPT,” which stands for “Generative Pre–Trained Transformer”).
Transformers are relatively recent (introduced in 2017 by several Google researchers in a famous paper called “Attention Is All You Need”) and have two big advantages that led to the dramatic rise in AI capabilities: speed and contextualization.
Speed
Transformers require less training time than other neural networks because they process inputs (e.g., words) in parallel rather than sequentially. Previous neural-network architectures (such as recurrent neural networks) would process each word fragment one at a time and then run through the passage again with each subsequent word fragment added. This was quite slow computationally.
Contextualization
Transformers also have a self-attention mechanism. Essentially, with a self-attention mechanism, each word “knows about” all the other words in the passage and how they are related. This means that the model can build a complex, nuanced understanding of syntactic (grammar) or semantic (meaning) relationships between words, even when two words are far from one another in a long passage of text. This is a big innovation — the context window (which is somewhat like the human-working memory) becomes much larger due to the self-attention mechanism.
Thus, transformer-based AI systems can do more than just predict the next word in a sequence of words. They can understand the relationships between words throughout a passage and keep track of things like who did what, in order to produce a coherent, “intelligent” response(Previous AI systems would often lose track of such information and later in a paragraph mix things up.)
References
Baquero, Carlos. 2024. The energy footprint of humans and large language models. (June 2024). Retrieved Sep. 9, 2024 from https://cacm.acm.org/blogcacm/the-energy-footprint-of-humans-and-large-language-models/
Brown, Tom B. et al. 2020. Language models are few-shot learners. arXiv:2005.14165. Retrieved from https://arxiv.org/abs/2005.14165
Colis, Jaron. 2017. Glossary of deep learning: Word embedding. (April 18, 2017). Retrieved Sep. 9, 2024 from https://medium.com/deeper-learning/glossary-of-deep-learning-word-embedding-f90c3cec34ca
Lee, Timothy B. and Sean Trott. 2023. A jargon-free explanation of how AI large language models work. (July 2023). Retrieved Sep. 9, 2024 from https://arstechnica.com/science/2023/07/a-jargon-free-explanation-of-how-ai-large-language-models-work/
OpenAI. 2022. Introducing ChatGPT. (2022). Retrieved Sep. 9, 2024 from https://openai.com/index/chatgpt/
OpenAI. 2024. Learning to summarize with human feedback. (2020). Retrieved Sep. 9, 2024 from https://openai.com/index/learning-to-summarize-with-human-feedback/
OpenAI. 2024. OpenAI API Documentation. (2024). Retrieved Sep. 9, 2024 from https://platform.openai.com/docs/api-reference/chat/create#chat-create-temperature
Ouyang, Long et al. 2022. Training language models to follow instructions with human feedback. arXiv:2203.02155. Retrieved from https://arxiv.org/abs/2203.02155
Templeton, Adly et al. 2024. Scaling monosemanticity. (2024). Retrieved Sep. 9, 2024 from https://transformer-circuits.pub/2024/scaling-monosemanticity/
Trott, Sean. 2024. “Mechanistic interpretability” for LLMS, explained. (July 2024). Retrieved Sep. 9, 2024 from https://seantrott.substack.com/p/mechanistic-interpretability-for
Trott, Sean. 2024. Tokenization in large language models. (MAy 2024). Retrieved Sep. 9, 2024 from https://seantrott.substack.com/p/tokenization-in-large-language-models
Vaswani, Ashish, et al. 2017. Attention is all you need. arXiv:1706.03762. Retrieved from https://arxiv.org/abs/1706.03762
Wei, J., et al. (2022). Finetuned language models are zero-shot learners. arXiv preprint arXiv:2203.02155. Retrieved from https://arxiv.org/abs/2109.01652
Wells, Sarah. 2023. Generative AI’s energy problem today is foundational. (October 2023). Retrieved Sep. 9, 2024 from https://spectrum.ieee.org/ai-energy-consumption