
Over the last few years, Instagram Direct has grown to be a core part of sharing content and experiences with your close friends on Instagram. This isn’t a privilege we take lightly; it’s incredibly important that we deliver each message as reliably and as quickly as possible.
The Internet transfers data at the Speed of Light, but in many cases, due to large distances and network inefficiencies, the human eye can still pickup on the delay between a request’s start and finish. Additionally, network requests can fail for a wide variety of reasons, such as connection-loss or transient server issues. In this blog post, we’ll discuss Instagram’s infrastructure on iOS and Android to not only retry these actions, but also to make the whole experience feel much faster and reliable to the user.
Often, when someone is building a mobile app that wants to “mutate” state on the server (such as tell the server to send a message), they have their view layer initiate a network request. It doesn’t take long before the developer realizes that this request could easily take a second or two even in good network conditions.
A common pattern used to make it seem like the application is fast and responsive (i.e., reduce the user-perceived latency) is to “optimistically” guess the expected output of the successful request and immediately apply it to the view — all before the request is even made. We call this concept “optimistic state”.

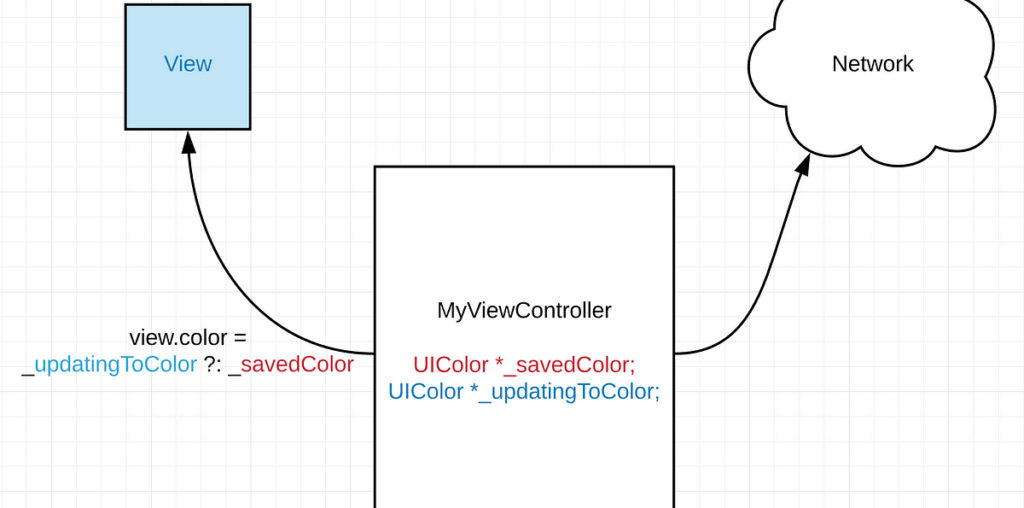
In this iOS example, I have an app that stores a color. The existing color, Red, is stored in _savedColor, but when MyViewController has set off a network request to change it, the app immediately overwrites the view’s color to Blue, in the _updatingToColor value. This makes the app feel much faster than waiting for the request to complete.
This pattern, however, becomes unmanageable as the application grows.
If I leave MyViewController, the other views in the app that depend on the same color value don’t reflect this ongoing request. This confuses the user, and makes the app look inconsistent, buggy, and slow! To handle this, many developers simply apply the Color change to the app’s global data-cache. In fact, Direct also used to apply optimistic changes to our global caches. But this poses many problems, too. What happens if some other event (such as fetching the Color from network) overwrites my ongoing-Blue color back to Red? This concept is referred to as “Clobbering”. It creates weird experiences for the user, and it’s difficult for developers to debug/reproduce.
Additionally, tying a network request to a short-lived ViewController causes its own set of issues. If my request fails for a retriable reason, such as a loss of network, we should be able to perform this request again later, even if MyViewController is deallocated.
As you can quickly see, optimistic state and network-request retry-logic are easy to build, but difficult to get right.
Given the number of different network conditions we must operate within, and the number of product surfaces we must support, building a consistent retry and optimistic state policy is a difficult task. To solve these problems, we built a piece of infrastructure that we call the Mutation Manager.
The Mutation Manager is designed to answer the questions above. Specifically, we wanted to make it effortless for mobile engineers to get:
- Intelligent and customizable auto-retry strategies for their network requests, with backoff behavior and retries across cold-starts.
- Optimistic State applied to all surfaces of the application, and free lifecycle management (adding, removing, handling clobbering, etc).
Direct’s Mutation Manager (or short: DMM) achieves these goals (and more) by creating a centralized service that owns the network requests, serializes them to disk for retries, and safely manages the flow of their resulting optimistic state.
In Instagram Direct, all surfaces implement this pattern. Let’s follow an example: imagine you navigate into a Direct thread with a message your friend just sent you. In that scenario, these steps occur:
- Submit a “Mark Thread as Read” mutation to the DMM.
- The DMM saves an entry into the OptimisticState cache. This entry is an instruction object, which describes the desired data change before the data is given to any UI.
- Mutation is saved to disk, in case we need to retry after an app termination such as a crash.
- The UI will then use ViewModels, which represent the merged state of the published-data and the entry that was saved to the OptimisticState cache.
- The network request is sent out. Each mutation has a MutationToken in its payload, which is a unique id created on the client.
- Once we have received the new confirmed state (with the matching MutationToken) from the server and updated the published-data, we remove and thus stop applying the entry from the optimistic state cache.

After all our mutations and surfaces were migrated to this pattern, optimistic state became an afterthought of product development, and yet all UX surfaces remain consistent and the app feels fast to the user. Since optimistic state and server data are stored separately, and only merged on-the-fly at the View layer, Clobbering is impossible.
Of course, nothing is free. The amount of client-side processing happening here has definitely increased. But, in practice, we’ve been able to mitigate any performance issues by keeping the application of the Optimistic State entry to the View Model as cheap as possible.
The DMM also preserves the order in which requests were sent, so mutations that should be visually ordered now get this support for free; for example, the DMM will only send the messages in the exact order in which the API was invoked, sending messages in the order that users expect a messaging service to work.
As seen above, there are many benefits to centralizing mutations and the flow of optimistic state. The Mutation Manager not only enforces good patterns for the app, but its also makes adding new mutations to this system extremely simple and quick. When adding a new mutation type, the compiler will guide you to answer all necessary questions about this request (network payloads, optimistic entries, etc). This ensures that as our team grows, our UX remains performant and reliable.
Let’s take the “Mark Thread as Read” mutation as an example. Previously, this mutation applied optimistic state directly to the Server-Data cache. As a result, that data could accidentally be clobbered back to an Unread state. To prevent this, we introduced merging logic directly in the Server-Data cache, which, while functional, was unfortunately quite complicated. However, once the mutation was moved onto the DMM, not only did it drastically simplify the merging logic, but it also resulted in a more consistent experience for the user.
Additionally, requests within the Mutation Manager are easier to debug. In our employee-only debug builds, the Mutation Manager logs events to a file that can be uploaded by the bug reporter. The engineer is then able to easily parse these logs and diagnose the request. In this example, we can see the request failed on the first attempt with a 500 error code, retried a second later, and succeeded.

As you can see, this infrastructure allows our product teams to move quickly without compromising performance and reliability. Check out our open engineering roles to join a fast-moving team at Instagram today.