
As discussed on Mozilla Connect, Firefox 130 will introduce an experimental new capability to automatically generate alt-text for images using a fully private on-device AI model. The feature will be available as part of Firefox’s built-in PDF editor, and our end goal is to make it available in general browsing for users with screen readers.
Why alt text?
Web pages have a fundamentally simple structure, with semantics that allow the browser to interpret the same content differently for different people based on their own needs and preferences. This is a big part of what we think makes the Web special, and what enables the browser to act as a user agent, responsible for making the Web work for people.
This is particularly useful for assistive technology such as screen readers, which are able to work alongside browser features to reduce obstacles for people to access and exchange information. For static web pages, this generally can be accomplished with very little interaction from the site, and this access has been enormously beneficial to many people.
But even for a simple static page there are certain types of information, like alternative text for images, that must be provided by the author to provide an understandable experience for people using assistive technology (as required by the spec). Unfortunately, many authors don’t do this: the Web Almanac reported in 2022 that nearly half of images were missing alt text.
Until recently it’s not been feasible for the browser to infer reasonably high quality alt text for images, without sending potentially sensitive data to a remote server. However, latest developments in AI have enabled this type of image analysis to happen efficiently, even on a CPU.
We are adding a feature within the PDF editor in Firefox Nightly to validate this approach. As we develop it further and learn from the deployment, our goal is to offer it for users who’d like to use it when browsing to help them better understand images which would otherwise be inaccessible.
Generating alt text with small open source models
We are using Transformer-based machine learning models to describe images. These models are getting good at describing the contents of the image, yet are compact enough to operate on devices with limited resources. While can’t outperform a large language model like GPT-4 Turbo with Vision, or LLaVA, they are sufficiently accurate to provide valuable insights on-device across a diversity of hardware.
Model architectures like BLIP or even VIT that were trained on datasets like COCO (Common Object In Context) or Flickr30k are good at identifying objects in an image. When combined with a text decoder like OpenAI’s GPT-2, they can produce alternative text with 200M or fewer parameters. Once quantized, these models can be under 200MB on disk, and run in a couple of seconds on a laptop – a big reduction compared to the gigabytes and resources an LLM requires.
Example Output
The image below (pulled from the COCO dataset) is described by:
- FIREFOX – our 182M parameters model using a Distilled version of GPT-2 alongside a Vision Transformer (ViT) image encoder.
- BASELINE MODEL – a slightly bigger ViT+GPT-2 model
- HUMAN TEXT – the description provided by the dataset annotator.

Both small models lose accuracy compared to the description provided by a person, and the baseline model is confused by the hands position. The Firefox model is doing slightly better in that case, and captures what is important.
What matters can be suggestive in any case. Notice how the person did not write about the office settings or the cherries on the cake, and specified that the candles were long.
If we run the same image on a model like GPT-4o, the results are extremely detailed:
The image depicts a group of people gathered around a cake with lit candles. The focus is on the cake, which has a red jelly topping and a couple of cherries. There are several lit candles in the foreground. In the background, there is a woman smiling, wearing a gray turtleneck sweater, and a few other people can be seen, likely in an office or indoor setting. The image conveys a celebratory atmosphere, possibly a birthday or a special occasion.
But such level of detail in alt text is overwhelming and doesn’t prioritize the most important information. Brevity is not the only goal, but it’s a helpful starting point, and pithy accuracy in a first draft allows content creators to focus their edits on missing context and details.
So if we ask the LLM for a one-sentence description, we get:
A group of people in an office celebrates with a lit birthday cake in the foreground and a smiling woman in the background.
This has more detail than our small model, but can’t be run locally without sending your image to a server.
Small is beautiful
Running inference locally with small models offers many advantages:
- Privacy: All operations are contained within the device, ensuring data privacy. We won’t have access to your images, PDF content, generated captions, or final captions. Your data will not be used to train the model.
- Resource Efficiency: Small models eliminate the need for high-powered GPUs in the cloud, reducing resource consumption and making it more environmentally friendly.
- Increased Transparency: In-house management of models allows for direct oversight of the training datasets, offering more transparency compared to some large language models (LLMs).
- Carbon Footprint Monitoring: Training models in-house facilitates precise tracking of CO2 emissions using tools such as CodeCarbon.
- Ease of Improvement: Since retraining can be completed in less than a day on a single piece of hardware, it allows for frequent updates and enhancements of the model.
Integrating Local Inference into Firefox
Extending the Translations inference architecture
Firefox Translations uses the Bergamot project powered by the Marian C++ inference runtime. The runtime is compiled into WASM, and there’s a model file for each translation task.
For example, if you run Firefox in French and visit an English page, Firefox will ask if you want to translate it to French and download the English-to-French model (~20MiB) alongside the inference runtime. This is a one-shot download: translations will happen completely offline once those files are on disk.
The WASM runtime and models are both stored in the Firefox Remote Settings service, which allows us to distribute them at scale and manage versions.
The inference task runs in a separate process, which prevents the browser or one of its tabs from crashing if the inference runtime crashes.
ONNX and Transformers.js
We’ve decided to embed the ONNX runtime in Firefox Nightly along with the Transformers.js library to extend the translation architecture to perform different inference work.
Like Bergamot, the ONNX runtime has a WASM distribution and can run directly into the browser. The ONNX project has recently introduced WebGPU support, which will eventually be activated in Firefox Nightly for this feature.
Transformers.js provides a Javascript layer on top of the ONNX inference runtime, making it easy to add inference for a huge list of model architectures. The API mimics the very popular Python library. It does all the tedious work of preparing the data that is passed to the runtime and converting the output back to a usable result. It also deals with downloading models from Hugging Face and caching them.
From the project’s documentation, this is how you can run a sentiment analysis model on a text:
import { pipeline } from '@xenova/transformers';
// Allocate a pipeline for sentiment-analysis
let pipe = await pipeline('sentiment-analysis');
let out = await pipe('I love transformers!');
// [{'label': 'POSITIVE', 'score': 0.999817686}]
Using Transformers.js gives us confidence when trying out a new model with ONNX. If its architecture is listed in the Transformers.js documentation, that’s a good indication it will work for us.
To vendor it into Firefox Nightly, we’ve slightly changed its release to distribute ONNX separately from Transformers.js, dropped Node.js-related pieces, and fixed those annoying eval() calls the ONNX library ships with. You can find the build script here which was used to populate that vendor directory.
From there, we reused the Translation architecture to run the ONNX runtime inside its own process, and have Transformers.js run with a custom model cache system.
Model caching
The Transformers.js project can use local and remote models and has a caching mechanism using the browser cache. Since we are running inference in an isolated web worker, we don’t want to provide access to the file system or store models inside the browser cache. We also don’t want to use Hugging Face as the model hub in Firefox, and want to serve model files from our own servers.
Since Transformers.js provides a callback for a custom cache, we have implemented a specific model caching layer that downloads files from our own servers and caches them in IndexedDB.
As the project grows, we anticipate the browser will store more models, which can take up significant space on disk. We plan to add an interface in Firefox to manage downloaded models so our users can list them and remove some if needed.
Fine-tuning a ViT + GPT-2 model
Ankur Kumar released a popular model on Hugging Face to generate alt text for images and blogged about it. This model was also published as ONNX weights by Joshua Lochner so it could be used in Transformers.js, see https://huggingface.co/Xenova/vit-gpt2-image-captioning
The model is doing a good job – even if in some cases we had better results with https://huggingface.co/microsoft/git-base-coco – But the GIT architecture is not yet supported in ONNX converters, and with less than 200M params, most of the accuracy is obtained by focusing on good training data. So we have picked ViT for our first model.
Ankur used the google/vit-base-patch16-224-in21k image encoder and the GPT-2 text decoder and fine-tuned them using the COCO dataset, which is a dataset of over 120k labeled images.
In order to reduce the model size and speed it up a little bit, we’ve decided to replace GPT-2 with DistilGPT-2 — which is 2 times faster and 33% smaller according to its documentation.
Using that model in Transformers.js gave good results (see the training code at GitHub – mozilla/distilvit: image-to-text model for PDF.js).
We further improved the model for our use case with an updated training dataset and some supervised learning to simplify the output and mitigate some of the biases common in image to text models.
Alt text generation in PDF.js
Firefox is able to add an image in a PDF using our popular open source pdf.js library:
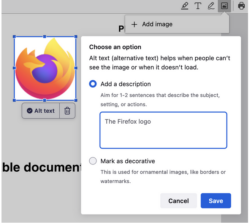
Starting in Firefox 130, we will automatically generate an alt text and let the user validate it. So every time an image is added, we get an array of pixels we pass to the ML engine and a few seconds after, we get a string corresponding to a description of this image (see the code).
The first time the user adds an image, they’ll have to wait a bit for downloading the model (which can take up to a few minutes depending on your connection) but the subsequent uses will be much faster since the model will be stored locally.
In the future, we want to be able to provide an alt text for any existing image in PDFs, except images which just contain text (it’s usually the case for PDFs containing scanned books).
Next steps
Our alt text generator is far from perfect, but we want to take an iterative approach and improve it in the open. The inference engine has already landed in Firefox Nightly as a new ml component along with an initial documentation page.
We are currently working on improving the image-to-text datasets and model with what we’ve described in this blog post, which will be continuously updated on our Hugging Face page.
The code that produces the model lives in Github https://github.com/mozilla/distilvit and the web application we’re building for our team to improve the model is located at https://github.com/mozilla/checkvite. We want to make sure the models and datasets we build, and all the code used, are made available to the community.
Once the alt text feature in PDF.js has matured and proven to work well, we hope to make the feature available in general browsing for users with screen readers.
Senior Staff Machine Learning Engineer working on Firefox & Python expert.