
Between Dec 2020 and May 2022, the Etsy Payments Platform, Database Reliability Engineering and Data Access Platform teams moved 23 tables, totaling over 40 billion rows, from four unsharded payments databases into a single sharded environment managed by Vitess. While Vitess was already managing our database infrastructure, this was our first usage of vindexes for sharding our data.
This is part 3 in our series on Sharding Payments with Vitess. In the first post, we focused on challenges in the application and data model. In part two, we discussed the challenges of cutting over a crucial high traffic system, and in this final post we will discuss different classes of errors that might crop up when cutting over traffic from an unsharded keyspace to a sharded keyspace.
As an engineer on Etsy’s Data Access Platform team, my role bridges the gap between product engineering and infrastructure. My team builds and maintains Etsy’s in-house ORM, and we are experts in both software engineering and the database software that our code relies on. Myself and members of my team have upstreamed over 30 patches to Vitess main. We also maintain an internal fork of Vitess, containing a handful of patches necessary to adapt Vitess to the specifics of our infrastructure. In our sharding project, my role was to ensure that the queries our ORM generates would be compatible with vindexes and to ensure that we configured Vitess correctly to preserve all of the data guarantees that our application expects.
Cutover risks
Vitess does an excellent job of abstracting the concept of sharding. At a high level, Vitess allows your application to interact with a sharded keyspace much the same as it would with an unsharded one. However, in our experience sharding with Vitess, we found a few classes of errors in which things could break in new ways after cutting over to the sharded keyspace. Below, we will discuss these classes of errors and how to reduce the risk of encountering them.
Transaction mode errors
When sharding data with Vitess, your choice of transaction_mode is important, to the extent that you care about atomicity. The transaction_mode setting is a VTGate flag. The default value is multi, which allows for transactions to span multiple shards. The documentation notes that “partial commits are possible” when using multi. In particular, when a transaction fails in multi mode, writes may still be persisted on one or more shards. Thus, the usual atomicity guarantees of database transactions change significantly: typically when transactions fail, we expect no writes to be persisted.
Using Vitess’s twopc (two-phase commit) transaction mode solves this atomicity problem, but as Vitess documentation notes, “2PC is an experimental feature and is likely not robust enough to be considered production-ready.” “Transaction commit is much slower when using 2PC,” say the docs. “The authors of Vitess recommend that you design your VSchema so that cross-shard updates (and 2PC) are not required.” As such, we did not seriously consider using it.
Given the shortcomings of the multi and twopc transaction modes, we opted for single transaction mode instead. With single mode, all of the usual transactional guarantees are maintained, but if you attempt to query more than one shard within a database transaction, the transaction will fail with an error. We decided that the semantics of single as compared with multi would be easier to communicate to product developers who are not database experts, less surprising, and provide more useful guarantees.
Using the single transaction mode is not all fun and games, however. There are times when it can seem to get in the way. For instance, a single UPDATE statement which touches records on multiple shards will fail in single mode, even if the UPDATE statement is run with autocommit. While this is understandable, sometimes it is useful to have an escape hatch. Vitess provides one, with an API for changing the transaction mode per connection at runtime via SET transaction_mode=? statements.
Your choice of transaction mode is not very important when using Vitess with an unsharded keyspace – since there is only a single database, it would be impossible for a transaction to span multiple databases. In other words, all queries will satisfy the single transaction mode in an unsharded keyspace. But when using Vitess with a sharded keyspace, the choice of transaction mode becomes relevant, and your transactions could start failing if they issue queries to multiple shards. To minimize our chances of getting a flood of transaction mode errors at our cutover, we exhaustively audited all of the callsites in our codebase that used database transactions. We logged the SQL statements that were executed and pored over them manually to determine which shards they would be routed to. Luckily, our codebase uses transactions relatively infrequently, since we can get by with autocommit in most cases. Still it was a painstaking process. In the end, our hard work paid off: we did not observe any transaction mode-related errors at our production cutover.
Reverse VReplication breaking
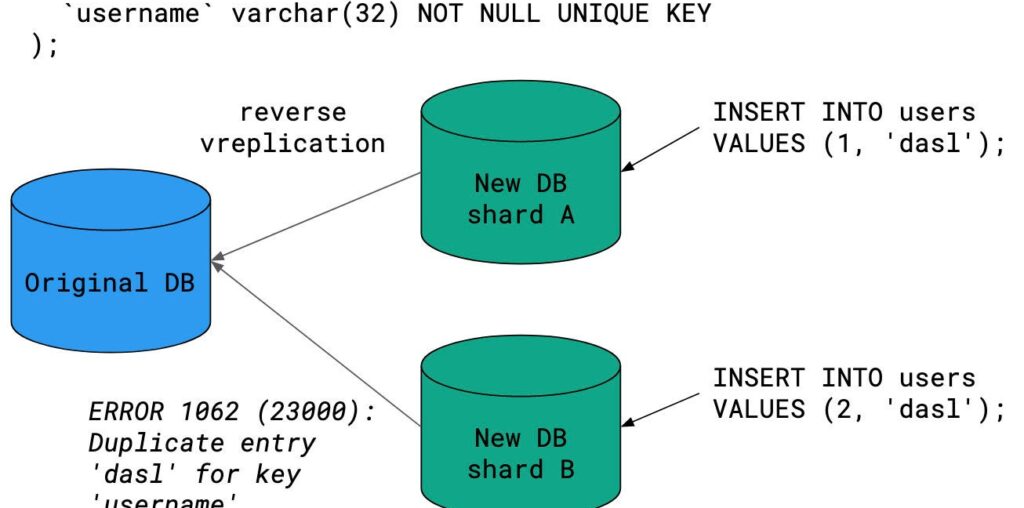
Pre-cutover, VReplication copies data from the original unsharded keyspace to the new sharded keyspace, to keep the data in sync. Post-cutover, VReplication switches directions: it copies data back from the new sharded keyspace to the original unsharded keyspace. We’ll refer to this as reverse VReplication. This ensures that if the cutover needs to be reversed, the original keyspace is kept in sync with any writes that were sent to the sharded keyspace. If reverse VReplication breaks, a reversal of the cutover may not be possible.
Reverse VReplication broke several times in our development environment due to enforcement of MySQL unique keys. In an unsharded keyspace, a unique key in your MySQL schema enforces global uniqueness. In a sharded keyspace, unique keys can only enforce per-shard uniqueness. It is perfectly possible for two shards to share the same unique key for a given row. When reverse VReplication attempts to write such rows back to the unsharded database, one of those writes will fail, and reverse VReplication will grind to a halt.

This form of broken VReplication can be fixed in one of two ways:
- Delete the row corresponding to the write that succeeded in the unsharded keyspace. This will allow the subsequent row to reverse vreplicate without violating the unique-key constraint.
- Skip the problematic row by manually updating the Pos column in Vitess’s internal
_vt.vreplicationtable.
It was important to us that reverse VReplication be rock solid for our production cutover. We didn’t want to be in a situation where we would be unable to reverse the cutover in the event of an unexpected problem. Thus, before our production cutover, we created alerts that would page us if reverse VReplication broke. Furthermore, we had a runbook that we would use to fix any issues with reverse VReplication. In the end, reverse VReplication never broke in production. The reason it broke in our development environment, it turned out, was due to a workflow specific to that environment.
As an aside, we later discovered that Vitess does in fact provide a mechanism for enforcing global uniqueness on a column in a sharded keyspace.
Scatter queries
In a sharded keyspace, if you forget to include the sharding key (or another vindexed column) in your query’s WHERE clause, Vitess will default to sending the query to all shards. This is known as a scatter query. Unfortunately, it can be easy to overlook adding the sharding key to one or more of your queries before the cutover, especially if you have a large codebase with many types of queries. The situation might only become obvious to you after cutover to the sharded cluster. If you start seeing a much higher than expected volume of queries post-cutover, scatter queries are likely the cause. See part 2 in this series of posts for an example of how we were impacted by scatter queries in one cutover attempt.
Having scatter queries throw a wrench in one of our earlier cutover attempts got us thinking about how we could identify them more easily. Vitess provides several tools that can show its execution plan for a given query, including whether or not it will scatter: vtexplain, EXPLAIN FORMAT=vitess …, and EXPLAIN FORMAT=vtexplain. At the time of our earlier cutover, we had not been in the habit of regularly analyzing our queries with these tools. We used them before the next cutover attempt, though, and made sure all the accidental scatter queries got fixed.
Useful as Vitess query analysis is, there is always some chance an accidental scatter query will slip through and surprise you during a production cutover. Scatter queries have a multiplicative impact: they are executed on every shard in your keyspace, and at a high enough volume can push the aggregate query volume in your sharded keyspace to be several times what you would see in an unsharded one. If query volume is sufficient to overwhelm all shards after the cutover, accidental scatter queries can result in a total keyspace outage. It seemed to us it would limit the problem if Vitess had a feature to prevent scatter queries by default. Instead of potentially taking down the entire sharded keyspace in a surge of query traffic, with a no-scatter default only accidental scatter queries would fail.
At our request, PlanetScale later implemented a feature to prevent scatter queries. The feature is enabled by starting VTGate with the –no_scatter flag. Scatter queries are still allowed if a comment directive is included in the query: /*vt+ ALLOW_SCATTER */. While this feature was not yet available during our earlier cutover attempts, we have since incorporated it into our Vitess configuration.
Incompatible queries
Some types of SQL queries that work on unsharded keyspaces are incompatible with sharded keyspaces. Those queries can start failing after cutover. We ran into a handful of them when we tested queries in our development environment. One such class of queries were scatter queries with a GROUP BY on a VARCHAR column. As an example, consider a table in a sharded keyspace with the following schema:
CREATE TABLE `users` (
`user_id` int(10) unsigned NOT NULL,
`username` varchar(32) NOT NULL,
`status` varchar(32) NOT NULL,
PRIMARY KEY (`user_id`)
)Assume the users table has a primary vindex on the column user_id and no additional vindexes. On such a table in a sharded keyspace, the following query will be a scatter query:
SELECT status, COUNT(*) FROM users GROUP BY status;This query failed with an error on our version of Vitess: ERROR 2013 (HY000): Lost connection to MySQL server during query.
After diving into Vitess’s code to determine the cause of the error, we came up with a workaround: we could CAST the VARCHAR column to a BINARY string:
> SELECT CAST(status AS BINARY) AS status, COUNT(*) FROM users GROUP BY status;
+----------+----------+
| status | count(*) |
+----------+----------+
| active | 10 |
| inactive | 2 |
+----------+----------+We occasionally ran into edge cases like this where Vitess’s query planner did not support specific query constructs. But Vitess is constantly improving its SQL compatibility – in fact, this specific bug was fixed in later versions of Vitess.
In our development environment, we exhaustively tested all queries generated by our application for compatibility with the new sharded keyspace. Thanks to this careful testing, we managed to identify and fix all incompatible queries before the production cutover.
Conclusion
There are several classes of errors that might only start appearing after the cutover from an unsharded keyspace to a sharded keyspace. This makes cutover a risky process. Although cutovers can generally be easily reversed, so long as reverse VReplication doesn’t break, the impact of even a short disruption can be large, depending on the importance of the data being migrated. Through careful testing before cutover, you can reduce your exposure to these classes of errors and guarantee yourself a much more peaceful cutover.
This is part 3 in our series on Sharding Payments with Vitess. Check out part 1 to read about the challenges of migrating our data models and part 2 to read about the challenges of cutting over a crucial high-traffic system.