
There are lots of articles about RAG (Retrieval Augmented Generation) explaining how to do it and more. Some of these articles are AI-generated, I presume. I haven’t written any article about this yet. This article will not be a tutorial, as you can easily find those on Medium and other platforms. Instead, I want to share the experiences and challenges I encountered during the app development with RAG.
I tested the RAG (Retrieval Augmented Generation) method several months ago. The first concept came to mind when I used ChatPDF.
Original language models like GPT-3.5, Gemini, Claude, or Llama don’t know everything, even though they were trained on billions of internet articles. If they don’t know, sometimes they say they don’t know. But sometimes, they hallucinate (give random answers) when you have high temperature in the model’s parameter setting.
It’s like a student bluffing when he/she doesn’t know the correct answer.
One way to control this hallucination is to provide additional context along with our question, which is like giving a book to a student and letting him/her find the answer in the book.
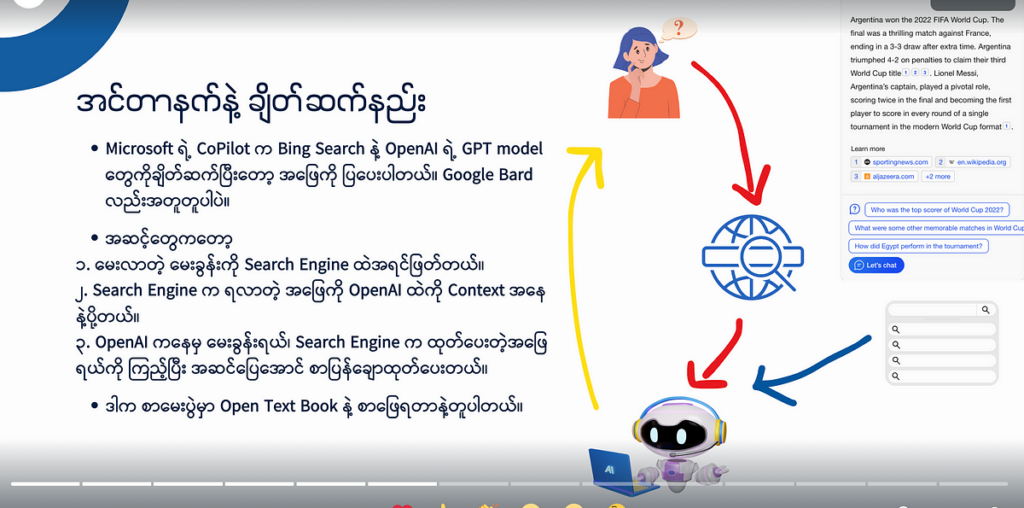
There are several effective ways we use today. Some of them utilize internet search engines or search in the database.
The number one approach is straightforward. Before we send a query to a language model, we pass it to a search engine first and use the search results as context.

The second approach is searching through the database. This is applied when you don’t want to use the public internet, working instead with an internal knowledge base. I’m seeing more and more use of the second approach in knowledge-based websites and apps. It also provides additional context to the AI before it gives a correct response.
However, there is a catch to the second approach.
It’s how much context you can send along with your question.
Think about this.
We allow students to answer the questions by referencing all textbooks in the library. That’s a huge amount of information. How would they search, and how many books do they need to reference to answer that? We can only allow them to note down references on one page.
Real RAG is about how to effectively retrieve relevant information from the reference articles within a limited context window. The context window I impose is a real issue in today’s language models. It’s the number of words an AI can manage to read the question and answer. Here are some references to learn about today’s LLM’s token limit. If the token exceeds that limit, an error will be thrown.

I was trying to create a chatbot for my fellow medical doctors to talk to a chatbot and get the information from the General Practitioner Guideline Book accurately. This book, prepared by the GP Society in Myanmar, would be really useful if primary care doctors used it to improve their practice.
The book was first in PDF format. Later, I got the DOCX file from the society.
RAG includes two parts: retrieval and augmentation.
The first part, retrieval, includes getting relevant information from the textbook. A normal keyword search might work, but not every time. When a doctor wants to ask a complex query or in natural language, it won’t work.
To apply RAG, this long PDF document had to be split into smaller parts, known as chunks. Remember the proverb?
“Don’t try to swallow the whole elephant at once, take a bite at a time.”
If we are splitting this PDF into chunks, where do we split? By chapter? Not efficient, as there are still a lot of pages in each chapter. By topics in each chapter?
Well, the ideal solution is to keep related context in one place and be as small as possible. If we can break it down into one page, that’s the best. But that requires lots of preprocessing work. PDFs are usually created from page makers or InDesign, often including two-column pages, images, and diagrams. It’s really difficult to split by context.
During my approach, I split by length (around 1000 tokens), using the Recursive Character Text Splitter. It totally neglected the relevance of context, solely depending on the length. It simplified the chunking process and gave me a bunch of separated chunks/pages around 1000 tokens each.
Whenever I search for something, the retriever will find it in all of those chunks/pages and retrieve the most related chunks with the highest matched scores. These chunks will be used as context to send to the LLM, and the LLM will prepare the final answer.
In this case, chunks are pages from opened textbooks, and the LLM is our student.
There is an additional process called vectorization, or embedding. This involves converting long texts (and audio, videos, images) and chunks to a series of decimal numbers.
The reason we have to use vectorization is for the machine to understand our natural language. Machines can’t process complex human scripts (English, Chinese, Burmese, etc.). If those are simplified into numerical vectors, machines can process faster and find relations. I converted the chunked texts to vectors and stored them in a vector database. Whenever I searched for something in natural language, that query was also converted to a vector by the LLM, and the retriever searched in the vector database and retrieved relevant chunks in vector form. Then the LLM converted the retrieved vector chunks to human-readable language.

I successfully tested RAG on the GP guideline book. I searched for something in natural language like “How do I treat a snake bite patient?” The chatbot pulled out the information from the GP book and prepared a great answer.

The main problem I encountered in my project was that sometimes information were missed, with low precision and low recall rates. Not all relevant information came through the retrieval engine. I found out the root cause later: it was because of my chunking method.
I chunked by text length, neglecting the context. That’s why the same chunk often included unrelated topics, and some important information was included in other chunks.
To solve this issue, I have to preprocess each chapter in markdown structure format. Then, the text splitter became easier to split using markdown tags, and the quality of the retrieval engine improved. Since the retrieval engine used cosine similarity as the default method, switching to another algorithm might improve the quality as well. But ,that process is labour intensive, unless every document is well defined .
I think this RAG method will be easier to embrace in internet documents which are well defined ,structured in separated documents.
I will try again in the future when I have more time, more resources or retrieval technology is improved. Until now, I stopped my work and switching my focus to other areas.
Hope you enjoy this article, please feel free to subscribe and give some claps .
Following is the video presentation.
https://www.youtube.com/watch?v=D6QE7jrnSDI
Thank you!
Nyein Chan Ko Ko
July 10 2024.