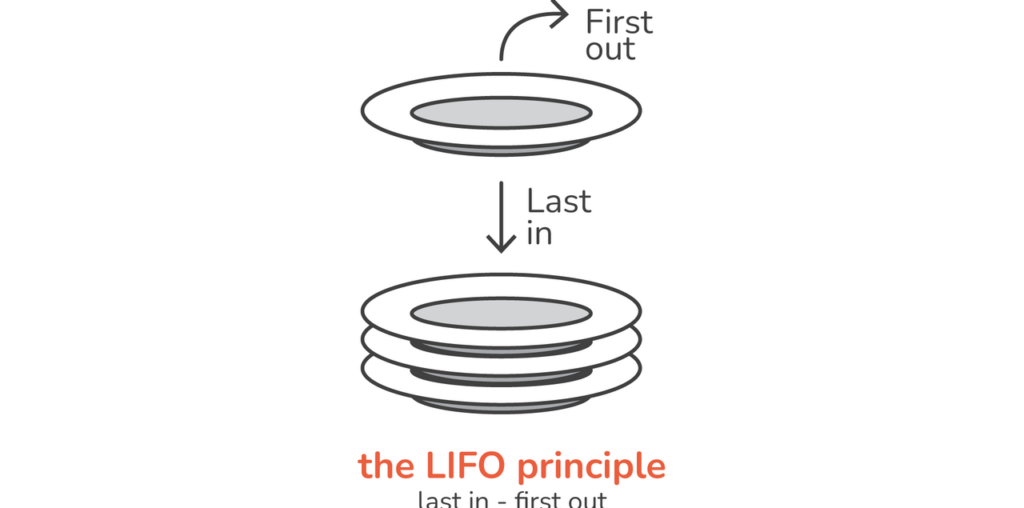

At its core, a stack is a linear data structure that follows the LIFO (Last In First Out) principle. Think of it as a stack of plates in a cafeteria; you only take the plate that’s on top, and when placing a new plate, it goes to the top of the stack.
The last element added is the first element to be removed

But, why is understanding the stack crucial? Over the years, stacks have found their applications in a plethora of areas, from memory management in your favorite programming languages to the back-button functionality in your web browser. This intrinsic simplicity, combined with its vast applicability, makes the stack an indispensable tool in a developer’s arsenal.
In this guide, we will deep dive into the concepts behind stacks, their implementation, use cases, and much more. We’ll define what stacks are, how they work, and then, we’ll take a look at two of the most common ways to implement stack data structure in Python.
Fundamental Concepts of a Stack Data Structure
At its essence, a stack is deceptively simple, yet it possesses nuances that grant it versatile applications in the computational domain. Before diving into its implementations and practical usages, let’s ensure a rock-solid understanding of the core concepts surrounding stacks.
The LIFO (Last In First Out) Principle
LIFO is the guiding principle behind a stack. It implies that the last item to enter the stack is the first one to leave. This characteristic differentiates stacks from other linear data structures, such as queues.
Note: Another useful example to help you wrap your head around the concept of how stacks work is to imagine people getting in and out of an elevator – the last person who enters an elevator is the first to get out!
Basic Operations
Every data structure is defined by the operations it supports. For stacks, these operations are straightforward but vital:
- Push – Adds an element to the top of the stack. If the stack is full, this operation might result in a stack overflow.

- Pop – Removes and returns the topmost element of the stack. If the stack is empty, attempting a pop can cause a stack underflow.

- Peek (or Top) – Observes the topmost element without removing it. This operation is useful when you want to inspect the current top element without altering the stack’s state.
By now, the significance of the stack data structure and its foundational concepts should be evident. As we move forward, we’ll dive into its implementations, shedding light on how these fundamental principles translate into practical code.
How to Implement a Stack from Scratch in Python
Having grasped the foundational principles behind stacks, it’s time to roll up our sleeves and delve into the practical side of things. Implementing a stack, while straightforward, can be approached in multiple ways. In this section, we’ll explore two primary methods of implementing a stack – using arrays and linked lists.
Implementing a Stack Using Arrays
Arrays, being contiguous memory locations, offer an intuitive means to represent stacks. They allow O(1) time complexity for accessing elements by index, ensuring swift push, pop, and peek operations. Also, arrays can be more memory efficient because there’s no overhead of pointers as in linked lists.
On the other hand, traditional arrays have a fixed size, meaning once initialized, they can’t be resized. This can lead to a stack overflow if not monitored. This can be overcome by dynamic arrays (like Python’s list), which can resize, but this operation is quite costly.
With all that out of the way, let’s start implementing our stack class using arrays in Python. First of all, let’s create a class itself, with the constructor that takes the size of the stack as a parameter:
class Stack:
def __init__(self, size):
self.size = size
self.stack = [None] * size
self.top = -1
As you can see, we stored three values in our class. The size is the desired size of the stack, the stack is the actual array used to represent the stack data structure, and the top is the index of the last element in the stack array (the top of the stack).
From now on, we’ll create and explain one method for each of the basic stack operations. Each of those methods will be contained within the Stack class we’ve just created.
Let’s start with the push() method. As previously discussed, the push operation adds an element to the top of the stack. First of all, we’ll check if the stack has any space left for the element we want to add. If the stack is full, we’ll raise the Stack Overflow exception. Otherwise, we’ll just add the element and adjust the top and stack accordingly:
def push(self, item):
if self.top == self.size - 1:
raise Exception("Stack Overflow")
self.top += 1
self.stack[self.top] = item
Now, we can define the method for removing an element from the top of the stack – the pop() method. Before we even try removing an element, we’d need to check if there are any elements in the stack because there’s no point in trying to pop an element from an empty stack:
def pop(self):
if self.top == -1:
raise Exception("Stack Underflow")
item = self.stack[self.top]
self.top -= 1
return item
Finally, we can define the peek() method that just returns the value of the element that’s currently on the top of the stack:
def peek(self):
if self.top == -1:
raise Exception("Stack is empty")
return self.stack[self.top]
And that’s it! We now have a class that implements the behavior of stacks using lists in Python.
Implementing a Stack Using Linked Lists
Linked lists, being dynamic data structures, can easily grow and shrink, which can be beneficial for implementing stacks. Since linked lists allocate memory as needed, the stack can dynamically grow and reduce without the need for explicit resizing. Another benefit of using linked lists to implement stacks is that push and pop operations only require simple pointer changes. The downside to that is that every element in the linked list has an additional pointer, consuming more memory compared to arrays.
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
As we already discussed in the “Python Linked Lists” article, the first thing we’d need to implement before the actual linked list is a class for a single node:
class Node:
def __init__(self, data):
self.data = data
self.next = None
This implementation stores only two points of data – the value stored in the node (data) and the reference to the next node (next).
Our 3-part series about linked lists in Python:
Now we can hop onto the actual stack class itself. The constructor will be a little different from the previous one. It will contain only one variable – the reference to the node on the top of the stack:
class Stack:
def __init__(self):
self.top = None
As expected, the push() method adds a new element (node in this case) to the top of the stack:
def push(self, item):
node = Node(item)
if self.top:
node.next = self.top
self.top = node
The pop() method checks if there are any elements in the stack and removes the topmost one if the stack is not empty:
def pop(self):
if not self.top:
raise Exception("Stack Underflow")
item = self.top.data
self.top = self.top.next
return item
Finally, the peek() method simply reads the value of the element from the top of the stack (if there is one):
def peek(self):
if not self.top:
raise Exception("Stack is empty")
return self.top.data
Note: The interface of both Stack classes is the same – the only difference is the internal implementation of the class methods. That means that you can easily switch between different implementations without the worry about the internals of the classes.
The choice between arrays and linked lists depends on the specific requirements and constraints of the application.
How to Implement a Stack using Python’s Built-in Structures
For many developers, building a stack from scratch, while educational, may not be the most efficient way to use a stack in real-world applications. Fortunately, many popular programming languages come equipped with in-built data structures and classes that naturally support stack operations. In this section, we’ll explore Python’s offerings in this regard.
Python, being a versatile and dynamic language, doesn’t have a dedicated stack class. However, its built-in data structures, particularly lists and the deque class from the collections module, can effortlessly serve as stacks.
Using Python Lists as Stacks
Python lists can emulate a stack quite effectively due to their dynamic nature and the presence of methods like append() and pop().
-
Push Operation – Adding an element to the top of the stack is as simple as using the
append()method:stack = [] stack.append('A') stack.append('B') -
Pop Operation – Removing the topmost element can be achieved using the
pop()method without any argument:top_element = stack.pop() -
Peek Operation Accessing the top without popping can be done using negative indexing:
top_element = stack[-1]
Using deque Class from collections Module
The deque (short for double-ended queue) class is another versatile tool for stack implementations. It’s optimized for fast appends and pops from both ends, making it slightly more efficient for stack operations than lists.
-
Initialization:
from collections import deque stack = deque() -
Push Operation – Similar to lists,
append()method is used:stack.append('A') stack.append('B') -
Pop Operation – Like lists,
pop()method does the job:top_element = stack.pop() -
Peek Operation – The approach is the same as with lists:
top_element = stack[-1]
When To Use Which?
While both lists and deques can be used as stacks, if you’re primarily using the structure as a stack (with appends and pops from one end), the deque can be slightly faster due to its optimization. However, for most practical purposes and unless dealing with performance-critical applications, Python’s lists should suffice.
Note: This section dives into Python’s built-in offerings for stack-like behavior. You don’t necessarily need to reinvent the wheel (by implementing stack from scratch) when you have such powerful tools at your fingertips.
Potential Stack-Related Issues and How to Overcome Them
While stacks are incredibly versatile and efficient, like any other data structure, they aren’t immune to potential pitfalls. It’s essential to recognize these challenges when working with stacks and have strategies in place to address them. In this section, we’ll dive into some common stack-related issues and explore ways to overcome them.
Stack Overflow
This occurs when an attempt is made to push an element onto a stack that has reached its maximum capacity. It’s especially an issue in environments where stack size is fixed, like in certain low-level programming scenarios or recursive function calls.
If you’re using array-based stacks, consider switching to dynamic arrays or linked-list implementations, which resize themselves. Another step in prevention of the stack overflow is to continuously monitor the stack’s size, especially before push operations, and provide clear error messages or prompts for stack overflows.
If stack overflow happens due to excessive recursive calls, consider iterative solutions or increase the recursion limit if the environment permits.
Stack Underflow
This happens when there’s an attempt to pop an element from an empty stack. To prevent this from happening, always check if the stack is empty before executing pop or peek operations. Return a clear error message or handle the underflow gracefully without crashing the program.
In environments where it’s acceptable, consider returning a special value when popping from an empty stack to signify the operation’s invalidity.
Memory Constraints
In memory-constrained environments, even dynamically resizing stacks (like those based on linked lists) might lead to memory exhaustion if they grow too large. Therefore, keep an eye on the overall memory usage of the application and the stack’s growth. Perhaps introduce a soft cap on the stack’s size.
Thread Safety Concerns
In multi-threaded environments, simultaneous operations on a shared stack by different threads can lead to data inconsistencies or unexpected behaviors. Potential solutions to this problem might be:
- Mutexes and Locks – Use mutexes (mutual exclusion objects) or locks to ensure that only one thread can perform operations on the stack at a given time.
- Atomic Operations – Leverage atomic operations, if supported by the environment, to ensure data consistency during push and pop operations.
- Thread-local Stacks – In scenarios where each thread needs its stack, consider using thread-local storage to give each thread its separate stack instance.
While stacks are indeed powerful, being aware of their potential issues and actively implementing solutions will ensure robust and error-free applications. Recognizing these pitfalls is half the battle – the other half is adopting best practices to address them effectively.