
Introduction
Slack handles a lot of log data. In fact, we consume over 6 million log messages per second. That equates to over 10 GB of data per second! And it’s all stored using Astra, our in-house, open-source log search engine. To make this data searchable, Astra groups it by time and splits the data into blocks that we refer to as “chunks”.
Initially, we built Astra with the assumption that all chunks would be the same size. However, that assumption has led to inefficiencies from unused disk space and resulted in extra spend for our infrastructure.
We decided to tackle that problem in a pursuit to decrease the cost to operate Astra.
The Problem with Fixed-Size Chunks
The biggest problem with fixed-sized chunks was the fact that not all of our chunks were fully utilized, leading to differently sized chunks. While assuming fixed-sized chunks simplified the code, it also led to us allocating more space than required on our cache nodes, resulting in unnecessary spend.
Previously, each cache node was given a fixed number of slots, where each slot would be assigned a chunk. While this simplified the code, it meant that undersized chunks of data would have more space allocated for them than required.
For instance, on a 3TB cache node, we would have 200 slots, where each slot was expected to hold a 15GB chunk. However, if any chunks were undersized (say 10GB instead of 15GB), this would result in extra space (5GB) being allocated but not used. On clusters where we’d have thousands of chunks, this quickly led to a rather large percentage of space being allocated but unused.
An additional problem with fixed-sized chunks was that some chunks were actually bigger than our assumed size. This could potentially happen whenever Astra created a recovery task to catch up on older data. We create recovery tasks based on the number of messages that we’re behind and not the size of data we’re behind. If the average size of each message is bigger than we expect, this can result in an oversized chunk being created, which is even worse than undersized chunks as it means we aren’t allocating enough space.
Designing Dynamic Chunks
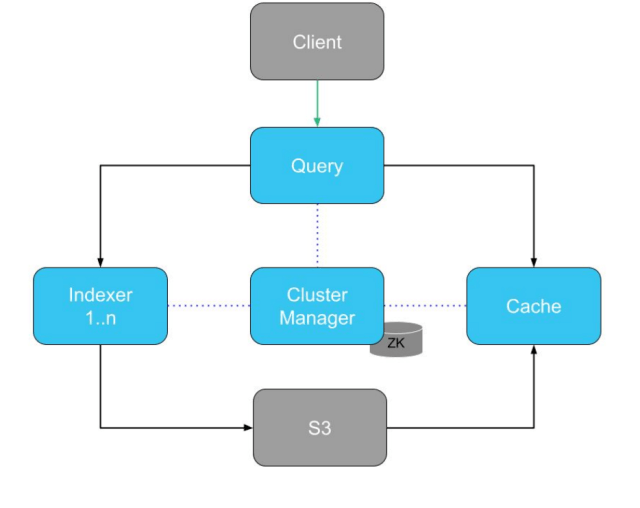
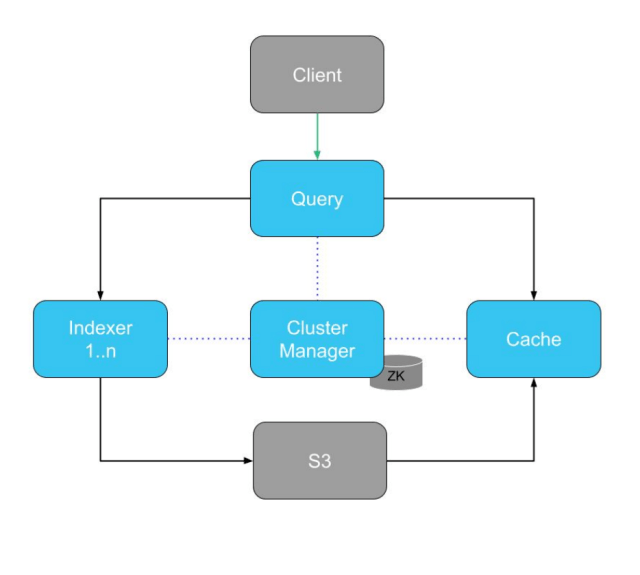 Astra’s architecture diagram – “ZK” is the Zookeeper store which holds metadata.
Astra’s architecture diagram – “ZK” is the Zookeeper store which holds metadata.
In order to build dynamic chunks, we had to modify two parts of Astra: the Cluster Manager and the Cache.
Redesigning Cache Nodes
We first looked at how cache nodes are structured: Previously, whenever a cache node came online, it would advertise its number of slots in Zookeeper (our centralized coordination store). Then, the Astra manager would assign each slot a chunk, and the cache node would go and download and serve that chunk.
Each cache node has a lifecycle:
- Cache node comes online, advertises the # of slots it has.
- Manager picks up on the slots, and assigns a chunk to each one.
- Each cache node downloads the chunks assigned to its slots.
This had the benefit of the slots being ephemeral, meaning whenever a cache node went offline, its slots would disappear from Zookeeper, and the manager would reassign the chunks the slots used to hold.
However, with dynamic chunks, each cache node could only advertise their capacity, as it would not know ahead of time how many chunks it would be assigned. This meant we unfortunately could no longer rely on slots to provide these benefits to us.
To fix these two problems, we decided to persist two new types of data in Zookeeper: the cache node assignment and the cache node metadata.
Here’s a quick breakdown:
- Cache Node Assignment: a mapping of chunk ID to cache node
- Cache Node Metadata: metadata about each cache node, including capacity, hostname, etc.
Utilizing these two new types of data, the new flow looks like this:
- Cache node comes online, advertises its disk space.
- Manager picks up on the disk space each cache node has, and creates assignments for each cache node, utilizing bin packing to minimize the number of cache nodes it uses.
- Cache nodes pick up on the assignments that were created for it, and downloads its chunks.
Redesigning the manager
The next change was in the manager, upgrading it to utilize the two new types of data we introduced: the cache node assignments and the cache node metadata.
To utilize the cache node assignments, we decided to implement first-fit bin packing to decide which cache node should be assigned which chunk. We then used the cache node metadata in order to make appropriate decisions regarding whether or not we could fit a certain chunk into a given cache node.
Previously, the logic for assigning slots was:
- Grab the list of slots
- Grab the list of chunks to assign
- Zip down both lists, assigning a slot to a chunk
Now, the logic looks like this:
- Grab list of chunks to assign
- Grab list of cache nodes
- For each chunk
- Perform first-fit bin packing to determine which cache node it should be assigned to
- Persist the mapping of cache node to chunk
Bin Packing
The most juicy part of redesigning the manager was implementing the first-fit bin packing. It’s a well-known problem of minimizing the number of bins (cache nodes) used to hold a certain amount of items (chunks). We decided to use first-fit bin packing, favoring it for its speed and ease of implementation.
Using pseudocode, we describe the bin-packing algorithm:
for each chunk
for each cache node
if the current chunk fits into the cache node:
assign the chunk
else:
move on to the next cache node
if there aren’t any cache nodes left and the chunk hasn’t been assigned:
create a new cache nodeThis helped ensure that we were able to pack the cache nodes as tightly as possible, resulting in a higher utilization of allocated space.
Rolling it out
Overall, this was a significant change to the Astra codebase. It touched many key parts of Astra, essentially rewriting all of the logic that handled the assignment and downloading of chunks. With such a change, we wanted to be careful with the roll out to ensure that nothing would break.
To ensure nothing would break we did the following:
- Hosted two replicas of the same data
- Placed all dynamic chunk code behind a feature flag
We leaned heavily on these two guardrails in order to ensure a safe roll out.
Hosting two replicas of the same data allowed us to incrementally deploy to one of the two replicas and monitor its behavior. It also ensured that if our changes ever broke anything, we’d still have a second replica able to serve the data.
Having all the code behind a feature flag allowed us to merge the code into master early on, as it wouldn’t run unless explicitly enabled. It also allowed us to incrementally roll out and test our changes. We started with smaller clusters, before moving on to bigger and bigger clusters after verifying everything worked.
Results
What kind of results did we end up seeing from this? For starters, we were able to reduce the # of cache nodes required by up to 50% for our clusters with many undersized chunks! Overall our cache node costs were reduced by 20%, giving us significant cost savings for operating Astra.
Acknowledgments
A huge shout out to everyone who has helped along the way to bring dynamic chunks to life:
- Bryan Burkholder
- George Luong
- Ryan Katkov
Interested in building innovative projects and making developers’ work lives easier? We’re hiring 💼