
Often when writing Combine-powered data pipelines, we want those pipelines to emit values as quickly as possible, as soon as each operation finishes. However, sometimes we might also want to introduce certain delays in order to prevent unnecessary work from being performed, or to be able to retry a failed operation after a certain amount of time.
One type of situation in which we might want to wait for a small amount of time before triggering a given pipeline is when our operations are based on some kind of free-form user input.
For example, let’s say that we’re building a controller that manages a list of items that are loaded from a Database, and that the user can choose to apply a string-based filter to the items that are being loaded.
To prevent too many database queries from being performed if the user rapidly types into the text field that our filter value is connected to, we could apply the debounce operator right before we perform our database call. That way, Combine will only continue executing our pipeline once no new values have come in for a certain amount of time (0,3 seconds in this case):
final class ItemListController: ObservableObject {
@Published private(set) var items = [Item]()
@Published var filter = ""
init(database: Database) {
$filter
.removeDuplicates()
.debounce(for: 0.3, scheduler: DispatchQueue.main)
.map(database.loadItemsMatchingFilter)
.switchToLatest()
.assign(to: &$items)
}
}To learn more about the above technique, including why the switchToLatest operator is used, check out “Connecting and merging Combine publishers in Swift”, which goes into much more detail on this topic.
Like its name implies, Combine’s built-in retry operator lets us automatically retry a pipeline’s operations if an error was encountered. When using it, we simply have to specify the maximum amount of retries that we’d like to perform, and Combine will take care of the rest. Here we’re using that operator within a customized version of the standard Combine-powered URLSession data task API, which will let us automatically retry any failed network request a certain amount of times:
extension URLSession {
func decodedDataTaskPublisher<T: Decodable>(
for url: URL,
retryCount: Int = 3,
decodingResultAs resultType: T.Type = T.self,
decoder: JSONDecoder = .init(),
returnQueue: DispatchQueue = .main
) -> AnyPublisher<T, Error> {
dataTaskPublisher(for: url)
.map(\.data)
.decode(type: T.self, decoder: decoder)
.retry(retryCount)
.receive(on: returnQueue)
.eraseToAnyPublisher()
}
}However, with the above implementation, each retry will be performed instantly as soon as an error was encountered, but what if we instead wanted to apply a certain delay between each retried operation?
For that, let’s turn to Combine’s delay operator, which lets us introduce a fixed amount of delay between two operations. Since we’re only looking to delay our retries in this case, we’ll use the catch operator to create a separate pipeline that applies our desired delay to a constant Void output value, and then calls flatMap to trigger our upstream pipeline once more — like this:
extension Publisher {
func retry<T: Scheduler>(
_ retries: Int,
delay: T.SchedulerTimeType.Stride,
scheduler: T
) -> AnyPublisher<Output, Failure> {
self.catch { _ in
Just(())
.delay(for: delay, scheduler: scheduler)
.flatMap { _ in self }
.retry(retries > 0 ? retries - 1 : 0)
}
.eraseToAnyPublisher()
}
}Note that we have to subtract 1 from the passed number of retries, since our flatMap operator will always run at least once. However, we also have to be careful not to turn that number negative, since that will cause Combine to perform an infinite number of retries.
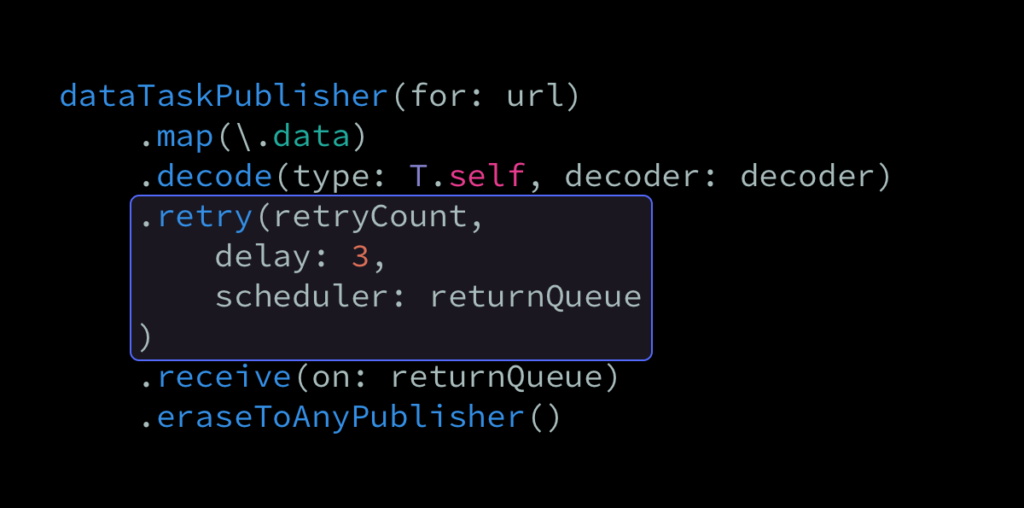
With the above in place, we can update our custom data task API from before to now look like this:
extension URLSession {
func decodedDataTaskPublisher<T: Decodable>(
for url: URL,
retryCount: Int = 3,
decodingResultAs resultType: T.Type = T.self,
decoder: JSONDecoder = .init(),
returnQueue: DispatchQueue = .main
) -> AnyPublisher<T, Error> {
dataTaskPublisher(for: url)
.map(\.data)
.decode(type: T.self, decoder: decoder)
.retry(retryCount, delay: 3, scheduler: returnQueue)
.receive(on: returnQueue)
.eraseToAnyPublisher()
}
}A three-second delay will now be applied between each retry, which is particularly useful in this case, since the user’s connection might’ve been temporarily offline when we first initiated our network call.
However, worth pointing out is that the above code sample is not meant to be a complete ready-to-use networking implementation, since we’d probably want to only retry when certain errors were encountered. For example, if we’re performing an authenticated network call and the user’s access token has become outdated, retrying such a call with the same parameters would just be a waste of battery and bandwidth.
To implement that kind of per-error logic, we could use the tryCatch operator instead, and then throw the errors that we don’t wish to perform a retry for. When doing that, our pipeline would immediately fail, and trigger whatever error handling that we’ve added at the call site.
Just like how we sometimes might want to introduce artificial delays within certain pipelines, there are also cases when we might want to completely defer a publisher’s execution until a subscriber was attached to it. This is exactly what the special Deferred publisher lets us do, which often becomes particularly useful when using Combine’s Future type.
For example, let’s say that we’re currently using Future to retrofit a FeaturedItemsLoader with Combine support — by sending the promise closure that’s passed into our future to our previous, closure-based API as a completion handler:
extension FeaturedItemsLoader {
var itemsPublisher: Future<[Item], Error> {
Future { [weak self] promise in
self?.loadItems(then: promise)
}
}
}The above works perfectly fine if we want each loading operation to start immediately, and if we never want to retry such an operation. However, doing something like the following won’t actually work as expected:
featuredItemsLoader.itemsPublisher
.retry(5)
.replaceError(with: [])
.sink { items in
...
}The reason the above doesn’t work is because a Future is always only run once, and then caches its result regardless if it succeeded or failed — meaning that even if the above pipeline will indeed be retried 5 times if an error was encountered, each of those retries will receive the exact same output from our Future-based itemsPublisher.
To fix that problem, let’s wrap our Future creation code within a Deferred publisher — which will both defer the creation of our underlying publisher until a subscriber started requesting values from it, and will also let us properly retry our pipeline, since doing so will now cause a new Future instance to be created for each retry:
extension FeaturedItemsLoader {
var itemsPublisher: AnyPublisher<[Item], Error> {
Deferred {
Future { [weak self] promise in
self?.loadItems(then: promise)
}
}
.eraseToAnyPublisher()
}
}However, while Deferred is incredibly useful, we shouldn’t necessarily use it every single time that we use a Future. Think of Deferred as the Combine equivalent of a lazy property — it doesn’t make sense to make every single property lazy, but it’s a useful tool to have in our toolbox for when we want the characteristics that lazy evaluation gives us.
Just like how Combine’s pipeline-oriented design can be truly wonderful when it comes to setting up reactive data flows and observations, it can also make implementing things like precise timing and retries a bit challenging, but hopefully this article has provided you with a few insights on how to do just that.
If you have any questions, comments, or feedback, then feel free to reach out via either Twitter or email. If you enjoyed this article and want to support my work, then a fantastic way to do so is to share this article with a friend or on social media.
Thanks for reading!